Blog
Cresta Conductor: The Agent for AI Agent Development
Cresta Conductor is a developer-first environment for building, testing, and improving production AI agents grounded in real customer conversations, business context, and Cresta’s enterprise deployment patterns.



Recap: Cresta at CCW Las Vegas 2026
Cresta hit CCW 2026 and soaked it all up - read a recap of our week at Contact Center Week


Cresta Unveils 3 Products to Strengthen AI Platform
Principal Analyst and CEO, Robin Gareiss of Metrigy, recaps Cresta's 3 AI Agent announcements and breaks down what this means for CX leaders


Cresta Conductor: The Agent for AI Agent Development
Cresta Conductor is a developer-first environment for building, testing, and improving production AI agents grounded in real customer conversations, business context, and Cresta’s enterprise deployment patterns.


The Data Comes First: Mining Real Conversations for Test Coverage
Learn how Cresta mines historical data, synthetic customers, knowledge-base Q&A pairs, and post-launch feedback to build test coverage that reflects how customers actually behave.


What 300 Leaders Told Us About the Future of Customer Experience Work
A preview of our new research into 300 CX, support, operations, and IT leaders, exploring how AI is reshaping customer experience work, changing the role of human agents, and redefining what it takes to scale customer experience effectively.


Introducing AI Agent Testing 2.0: Confidence at Launch, Confidence at Scale
Most AI agent testing programs peak on launch day. Requirements drift, evaluators lose signal, and coverage gaps widen as the agent evolves. Cresta AI Agent Testing 2.0 introduces a new architecture: AI-drafted requirements, calibrated LLM evaluators, and test coverage that builds itself from real production signal.


Evaluating Speech-to-Text Quality: Beyond Word Error Rate
A look at why Word Error Rate alone isn't enough to evaluate speech-to-text quality, and which metrics actually predict downstream AI performance in contact center environments.


Introducing Synthetic Customers: A Living Model of Your Customer Base, Derived From Real Conversations
Introducing Synthetic Customers: a new way to test AI agents, train human agents, pressure-test decisions, and understand your customer base — all from personas derived directly from your real conversation data.


Cresta Crew: Hanze Li, Forward Deployed Engineer
Learn about Cresta's Forward Deployed Engineering approach and team through the eyes of Hanze Li, a Forward Deployed Engineer.


The Three Pillars of Voice Integration: Building Hybrid AI Contact Centers That Work With Your Existing Infrastructure
Learn the three pillars of voice integration—and how to connect AI agents to your current systems with speed, flexibility, and confidence.

.webp)
Meet Customers Where They Are — When Their AI Is the One Calling
This blog explores how companies should prepare for a future of agent-led interactions, where automation removes friction, humans focus on moments that require trust and judgment, and oversight becomes essential to operating AI confidently at scale.


How to Make Sure Your Team Doesn’t Hang Up on the Pope
When Pope Leo XIV called his Chicago bank, he passed every security check — and still got hung up on. Read on for why CX has a lot to learn from Pope Leo.

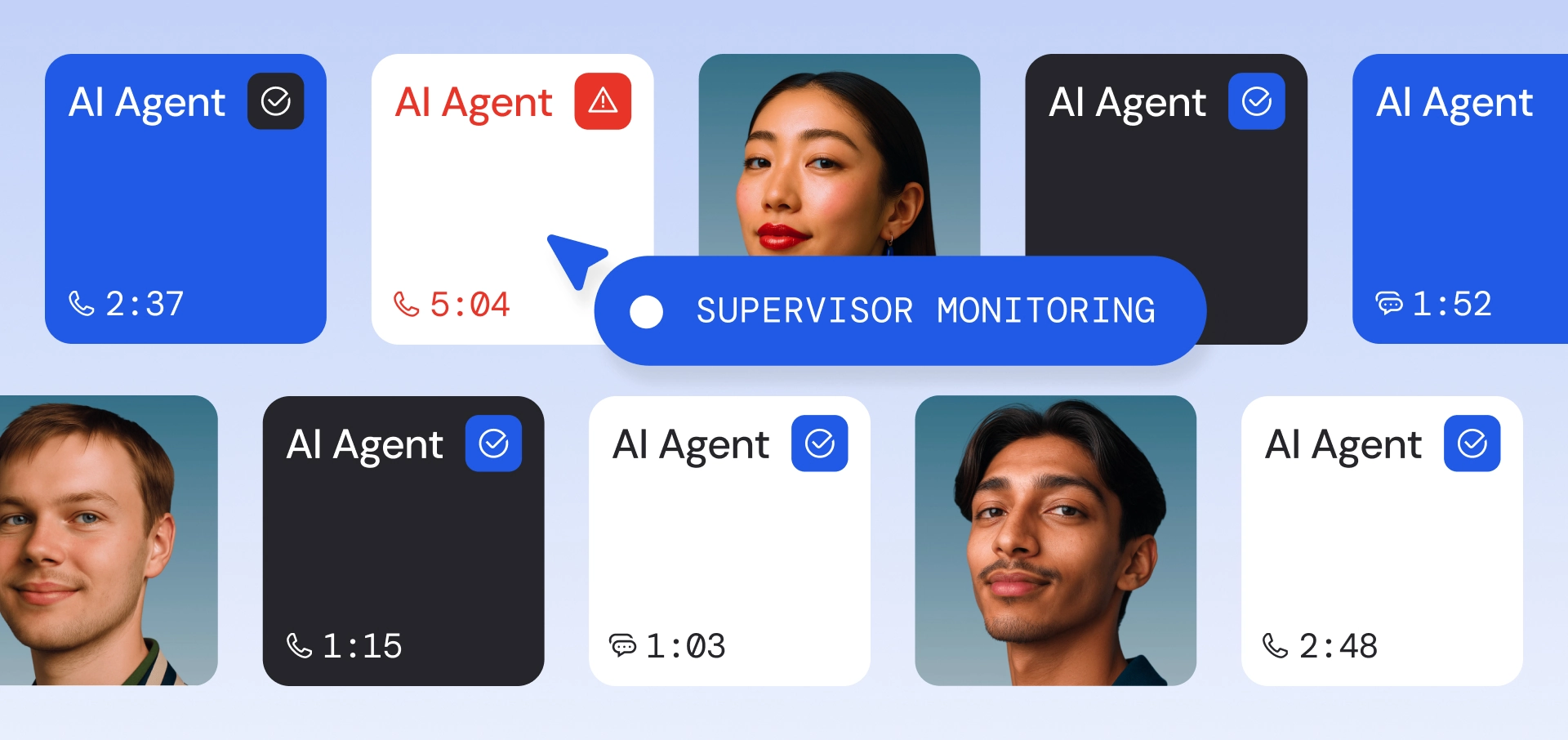
Designing the AI Agent Supervision Experience
Learn how Cresta's Product Design team translated five UX imperatives into the Agent Operations Center, giving supervisors real-time control to guide both AI agents and human agents.

.webp)


No Blog posts match your search
Try changing your search terms.
Ready to see the results for yourself?
See the unified platform for human and AI agents in action with a personalized demo
