
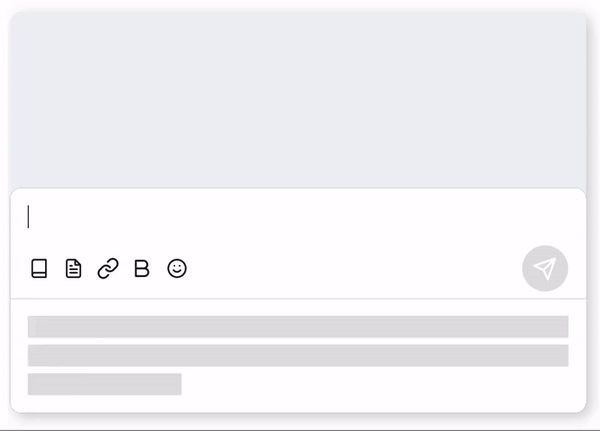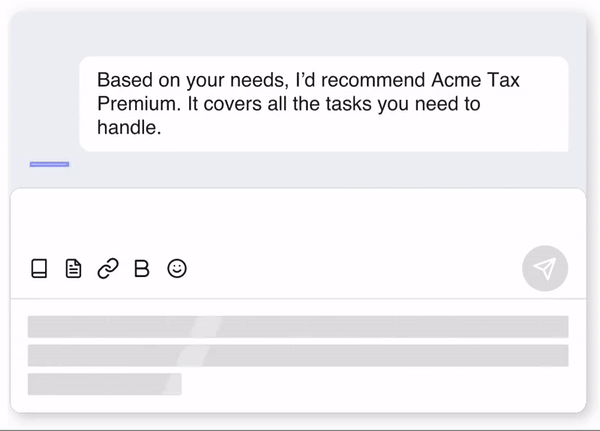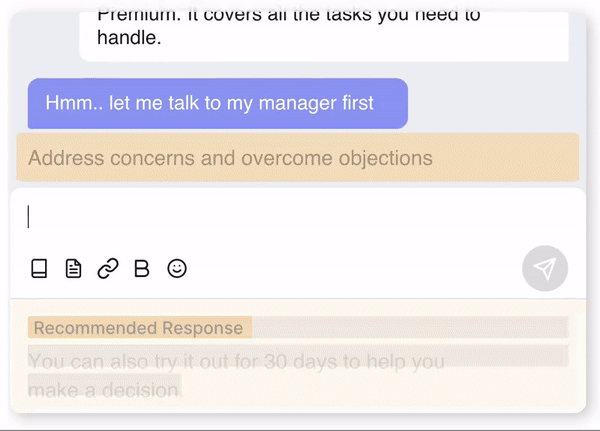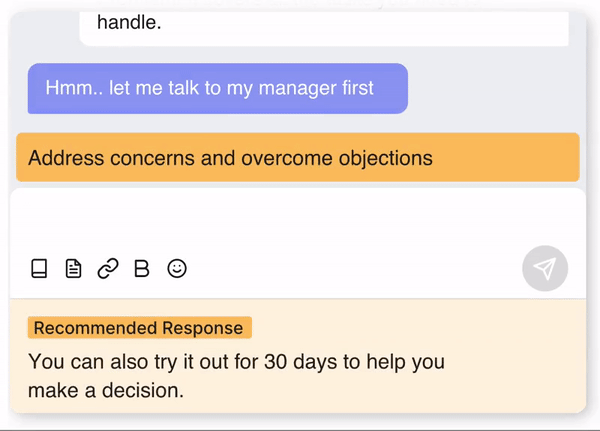
At Cresta, we are democratizing expertise for sales and support teams by making every agent an expert. To distill such expertise into software, we ask top agents to demonstrate, and in turn, help us label best practices. Machine Learning models are then trained for customers to maximize their KPIs. Our models continuously learn what top agents do differently and scale those behaviors across entire teams.Apart from providing goal-directed suggestions during ongoing live chats which we talked about in our recent Action Directed GPT-2 blogpost, another unique feature that Cresta offers is real-time coaching assist. As shown below, Cresta provides personalized coaching at key moments in a live chat, to inculcate the required behaviors for every agent to perform like a top agent.
The Real-time Coaching and Agent Assist features mentioned above are powered by our Natural Language Understanding (NLU) pipeline, which is responsible for producing models that help us understand and track the state of the conversation as a chat progresses between an agent and a visitor. The 2 most common tasks which our NLU pipeline solves for, are:
- Intent Classification: detecting the intent behind each message from both agent and visitor
- Chat Driver Classification: detecting and tracking the main objective behind the visitor reaching out
In 2019, as our customer base started to rapidly grow, one of the biggest challenges we faced was the time and effort required to label data required by our NLU Classification pipeline. To scale as a software company, we strive to maximize our speed of developing and iterating on the required models. In this blog post, we share how our classification pipeline evolved over time and how we reduced our labeling cost and efforts by over 10x, while continuously pushing our accuracy benchmarks forward.
Deep Transfer Learning
As was the case for most NLP pipelines across the world in 2019, the first big jump in efficiency came with the introduction of Deep Transfer Learning. Transfer learning, in the form of pre-trained language models, has revolutionized the field of NLP, leading to state-of-the-art results on a wide range of tasks. The idea is to first pre-train a model on a large unlabeled dataset using a language modeling objective, and then fine-tune it on a smaller labeled dataset using a supervised task of choice.


One-vs-all Classification
Buoyed by the success of the multi-head architecture, we turned our attention to a problem which was proving to be a costly step in our labeling process: handling a

To address the above challenge of iterating on a growing label taxonomy, we converted the multi-class classification problem to a

Multi-head BERT for One-vs-all Intent Classification[/caption]The above architecture gave us the flexibility of adding more classes as we iterated on the taxonomy required to produce the experience desired by our customers, without having having to re-label our existing dataset each time. This architecture could be used both for a single-task or in a multi-task setting by simply prepending the class name with the task name to create a unique identifier for each head.
Binary Labeling Interface with Loss Masking
Data labeling interfaces and best practices, in general, have been an under-researched area – as was touched upon by François Chollet's recent tweet, which sparked a debate amongst the research community. Our experience while trying to scale Machine Learning for business use-cases, pushed us to consider data curation and labeling as any other research problem we were looking to solve.Labeling cost has 2 dimensions – the number of labeled samples required and the average time required to "correctly" label a sample. We realized that the effort and cost required to reach a high quality labeled dataset was often turning out to be a costly step requiring multiple quality assurance iterations. With a much more flexible one-vs-all architecture, instead of just looking for ways to reduce the number of labeled samples required by our models, we started iterating on optimizing our labeling interface with the goal of reducing the difficulty of labeling a given sample.Humans usually have a small attention span, and labeling often can be a very tedious and mundane task. We A/B tested a new labeling interface where labelers would be making a single binary decision at a time, True/False for a pair of (sample, class), determining whether the sample belongs to that class or not.

A labeler could pick a class they wanted to focus on and the interface would present a sample to be labeled in a binary fashion, accompanied by clear labeling guidelines and examples, as shown in the image above. This interface allowed labelers to think about one class at a time, resulting in a lower cognitive load for them, while also allowing us to scale and distribute the labeling tasks more efficiently among the labelers. Our results showed that this interface resulted in ~2x faster labeling, with fewer mistakes made by the labelers.Integrating the Binary Labeling Interface with our one-vs-all architecture meant we had to solve 1 problem: there was no guarantee that for a given sample, all the classes would be labeled. More explicitly, given the large amount of unlabeled data we usually work with, the design choice of labeling one class per sample meant that it was highly likely that for a given labeled sample in our training set, we would not have a supervision signal for all the heads. To address this, we implemented Loss Masking, where for a given sample we masked the loss for all the heads we didn't have a label for. As demonstrated in the image below, for each sample, the loss is only applied to heads for which we have a label in the training batch.

Active Learning
Next, we turned our attention towards pushing the boundary around how sample-efficient Deep Transfer Learning could be, by introducing Active Learning in the pipeline. Our goal was to explore what can be achieved both in terms of accuracy and the associated labeling cost when these large pre-trained language models are used in conjunction with Active Learning techniques.Similar to how humans learn, giving a model the power to interactively query a human to obtain labels at certain data points – i.e. introducing human guidance at various intervals – can dramatically improve the learning process. This is the key idea behind

As described in the above plot using a toy dataset, choosing the optimal data points to label can dramatically reduce the amount of labeled data the model might need[/caption]Active Learning is an iterative process, which can be described by the following steps
- Step 1: Label a small set of data, instead of investing huge labeling resources and cost upfront
- Step 2: Train a model on the above and then use it to predict outputs on unlabeled data
- Step 3: From the predictions, select data points based on a sampling strategy (for example Uncertainty Sampling – which selects data points the model is most uncertain about) and label those to include in the training dataset
- Step 4: (Back to Step 2) Retrain the model with the updated dataset and repeat the rest of the steps until a satisfactory quality is achieved
Workflow Automation
Active Learning by definition involves a periodic human intervention in the process – which meant that for the above workflow to function effectively, we needed a single interface where our data team could seamlessly label new data points and immediately study its effect on the model to minimize the time delay between iterations.To achieve the above, we developed a single tool with the following features:
- Labeling
- Using offline-clustering or user-specified regexes, filter out samples to label (Bootstrapping)
- Using an existing model and a sampling strategy, filter out samples to label (Active Sampling)
- Dataset Updates & Training
- Have a single button (call to action) to create an updated labeled dataset from the available set of labels, fire a training run, and run the trained model on an unlabeled dataset to have it ready for Active Sampling
- Periodically pull in fresh unlabeled data from the customer, and run the latest model on it to have it ready for Active Sampling
- Model Evaluation
- For a trained model, calculate different accuracy metrics on a given dev/test set
- For a trained model, show misclassifications per class from a given dev/test set
[caption id="attachment_22789" align="aligncenter" width="751"]

Active Learning workflow automation[/caption]As shown in the above image, our goal was to automate as many steps as possible in the iterative workflow, maximizing the speed of iteration and minimizing the manual human effort required. The large pre-trained language models powering our classifiers are known to have a vast amount of world knowledge trapped inside them, allowing them to careers page for open positions.
Acknowledgments
Shubham Gupta for continuous contributions to the Active Learning workflow automation.Tim Shi for overseeing the various projects described in this blog post.Jessica Zhao, Lars Mennen, Motoki Wu, Saurabh Misra, Shubham Gupta and Tim Shi for edits and reviews on this blog post.
References
- Universal Language Model Fine-tuning for Text Classification (Howard and Ruder, 2018)
- The Natural Language Decathlon: Multitask Learning as Question Answering (McCann et al., 2018)
- Multi-Task Deep Neural Networks for Natural Language Understanding (Liu et al., 2019)
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin et al., 2018)
- In Defense of One-Vs-All Classification (Rifkin and Klautau, 2004)
- Active Learning Literature Survey (Settles, 2010)
- Language Models are Unsupervised Multitask Learners (Radford et al., 2019)


