
Cresta’s voice platform is a cutting-edge solution designed to provide real-time insights and actionable intelligence during customer interactions. It integrates with a wide variety of Contact Center as a Service (CCaaS) platforms, capturing and processing live audio streams to assist agents with timely guidance and recommendations. To shed light on the technology behind the scenes, we’ve divided our exploration into a three-part series.
Part One: Handling Incoming Traffic with Customer-Specific Subdomains
In this post, you’ll learn about how Cresta manages incoming traffic efficiently, including how customer-specific subdomains ensure scalability and isolation. We’ll explore the role of DNS, ingress controllers, and AWS Elastic Load Balancers in routing traffic to the right services.
Part Two: The Voice Stack
The second article focused on how the platform processes live audio streams through its voice stack and how business logic layers power real-time guidance for agents. This part highlights key components like speech recognition and how conversation data flows through the system.
Today’s installment will take you deeper into the machine learning (ML) stack, exploring how inference graphs orchestrate model workflows, how customer-specific policies influence ML processing, and how Cresta delivers actionable insights in real-time.
Quick recap
By now, reading the other two articles should provide some familiarity with the Cresta platform and the components used.
In the first two articles, we delved into how traffic flows from outside in to our clusters and the responsibilities of the voice stack and business logic layers of the platform. These layers are responsible for performing ASR (automatic speech recognition), audio redaction & persistence (`gowalter`) and transcript persistence (`apiserver`) as well as orchestrating the inference calls to the ML Services and publishing actions back to the client application.
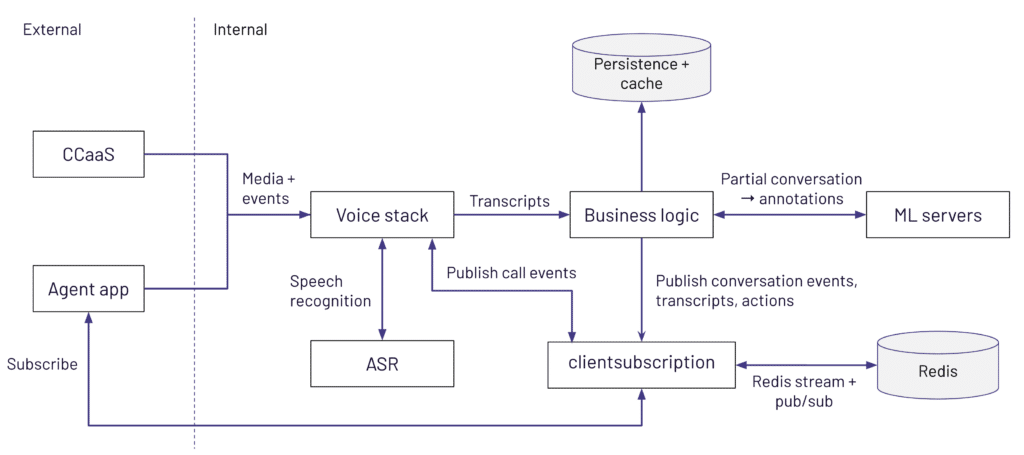
Serving
When a new or updated transcript arrives—whether partial or complete—the `orchestrator` is responsible for deciding which ML services need to be invoked and in what order. This can quickly become complex, because different customers, teams, or agents may need different configurations and sets of models.
Some conversations might call for generative AI models, while others might require custom or standard intent models to detect user intent. In addition, certain models may only run on partial transcripts (e.g., less expensive keyword detection) while others might only run on the final transcript (e.g., more advanced intent classification).
Behind the scenes, `orchestrator` determines the inference graph to apply via “search policies” in order to generate the final inference graph—a blueprint that outlines which ML services will be called and in what sequence. The machine learning services consist of different types of models to handle tasks like intent detection, sentiment analysis, entity extraction, and more.
The purpose of the policies is to specify the conditions under which certain models are used, such as particular agents, teams, or time intervals. `apiserver` is responsible for compiling the applicable policies for that specific conversation, caches them for easier retrieval. The policy is compiled just once for each conversation, before being cached.
This approach accommodates the dynamic nature of contact centers, where different teams (e.g., sales, retention) have distinct policies, and agents can transition between teams over time, requiring adjustments in the policies applied.
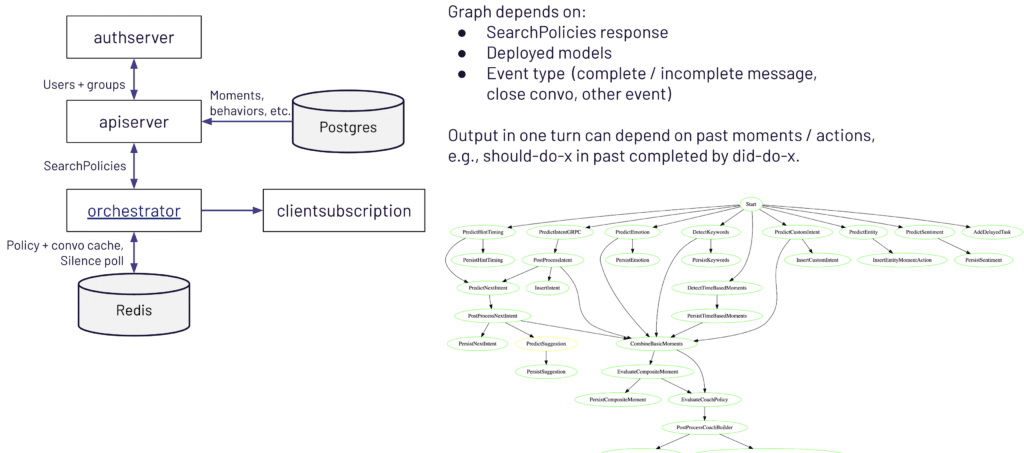
Because different customers may use different model combinations, the Orchestrator has to handle a wide variety of potential paths. For instance, some conversations might only need basic keyword detection, while others call for advanced sentiment analysis or sophisticated intent detection. The same conversation could also switch from partial to final transcripts, triggering new or different model calls. For example, for partial transcripts, faster models are used for efficiency.
All of this results in a dynamic, branching workflow that can feel complex, but ultimately ensures that each conversation gets exactly the ML processing it needs. The diagram above gives a high-level overview of these relationships and helps illustrate how the various components—Orchestrator, search policies, API server, and models—work together to serve up insights in real time.
ML Services
These ML Services are grouped into “shards”, with each shard potentially containing different models or supporting different customers. A shard corresponds to a Kubernetes pod. Not every pod will contain the same models; instead, shards are tailored to specific needs, often combining several models onto the same GPU (or multiple GPUs) for efficiency. Some shards may even run entirely on CPUs—it all depends on the workloads and model requirements.
In each deployment, there is a router component that directs requests to the appropriate shard. The router maintains an internal map of which shards serve which customers’ models. Once a request arrives, the router decides which shard can handle it and forwards it there.
Each shard also includes its own “envelope” process—think of this as a smaller, internal router that receives requests from the shard’s entry point and dispatches them to the correct Python processes running inside that same pod.
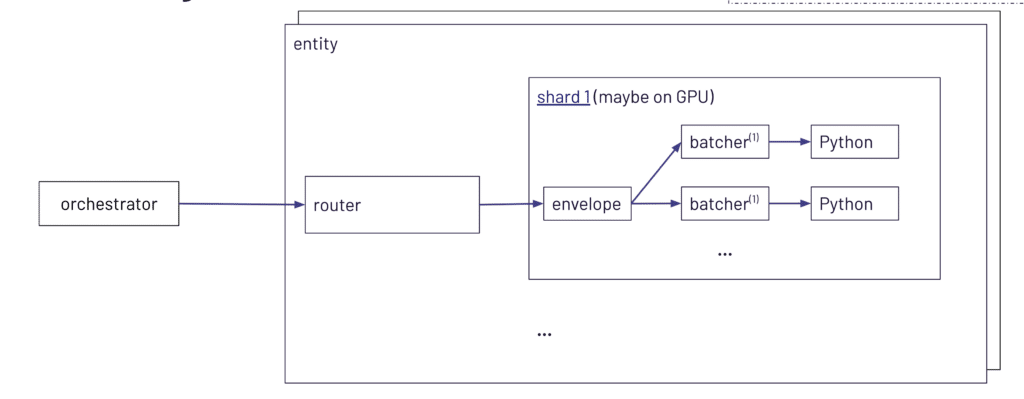
This design helps keep inference latency low in a cost-effective manner, because each request can be swiftly routed to the proper model without detours.
When large volumes of requests can arrive in bursts, there is also a “batcher” mechanism that collects incoming requests over a short window (a few hundred milliseconds) and then processes them all together. This approach further reduces overhead by taking advantage of batch inference capabilities on GPUs.
For real-time or “live” serving, however, the system remains highly latency-optimized, forwarding each request as soon as it comes in to the relevant Python service for fast turnaround.
All of this happens in real time during the conversation, for each utterance, with moments and actions being pushed back to the agent for low-latency conversational insights.
Ending the conversation
When a conversation ends, `gowalter` takes note and begins the final processing steps by encoding and compressing the audio, applying redaction and uploading it to S3.
Meanwhile, `apiserver` receives the “CloseConversation” event. It indexes conversation data in Elasticsearch for fast searching and stores analytics data in ClickHouse. This final phase is also when certain end-of-conversation features, like conversation summarization, get triggered and made available to the agent app.
Redaction is an important aspect of the platform, as we want to keep PII confidential. In the case of audio, beeps are applied, while for text it’s a simple text redaction for the entity, for example `[FULLNAME]`.
This can sometimes be imperfect in real time – for instance, if the entity recognition service misses something – so to ensure all data is properly redacted,`apiserver` spins up a Temporal workflow to double-check that no un-redacted data remains in the system. Temporal’s ability to retry ensures that even if redaction runs into errors—like partial failures or race conditions—it will keep trying until the conversation data is fully sanitized. If, for any reason, these repeated attempts still fail, a page is automatically sent to the on-call team so the issue can be addressed before any sensitive information is exposed or retained.


