At Cresta, we empower sales and support agents that talk to their customers over chat to become experts on day one. We do that by providing them real-time suggestions about how they should respond to their customers. The suggestions as shown in the image below are fully formed responses that can either be sent directly or after light editing by the agents.
Agents can choose to respond with these generated suggestions.
By suggesting great responses, we help sales agents sell more and help support agents resolve issues quickly. These suggestions also make agents more efficient by saving them a lot of time from manually typing responses.
With this blog, we would like to share an exciting new machine learning model we designed and deployed in early 2020, to generate these expert suggested responses which have driven improvements in sales conversion for our customers
But before introducing the new model, let’s understand the general problem we are trying to solve by focusing on the domain of sales.
ML for Sales Conversations
When a sales representative joins a new company, they spend about 6 months learning the ropes and gaining experience until becoming completely effective in their roles. Traditionally, the agents are coached by a sales leader who would listen to conversations and jump in at the right moment to guide the representative. The sales leader may tell the agent to take actions like “Ask for a sale”, “Discover customer’s needs”, “Greet the customer” etc. In the context of live chat, it’s valuable to have a real-time coach to guide responses.
Cresta’s platform helps to solve this training problem by creating individualized responses for each agent. At appropriate moments in the conversation, sales agents can use these suggestions to answer customer inquiries more quickly and more effectively. Our models analyze the ongoing sales conversation to understand the situation, and then suggest the next best response to say according to the next best action to take.
Language Models for Dialog
The problem of generating the next response can be solved by training a language model on a dataset of conversations. When we represent dialog as text, we can train a language model on that text and then ask the language model to generate the probable next response given an in-progress conversation. In practice, we have seen that this method works well as pre-trained language models have become very powerful in the past 2 years. These language models usually generate coherent responses.
But just generating coherent responses is not enough. We also want the system to generate the best response to reach the goal of successfully converting a sale. However, a major problem with such language models is that they are difficult to control. This means that it is hard to ask the model to generate a certain type of response.
Now, for example, imagine Alice and Bob are having a conversation…
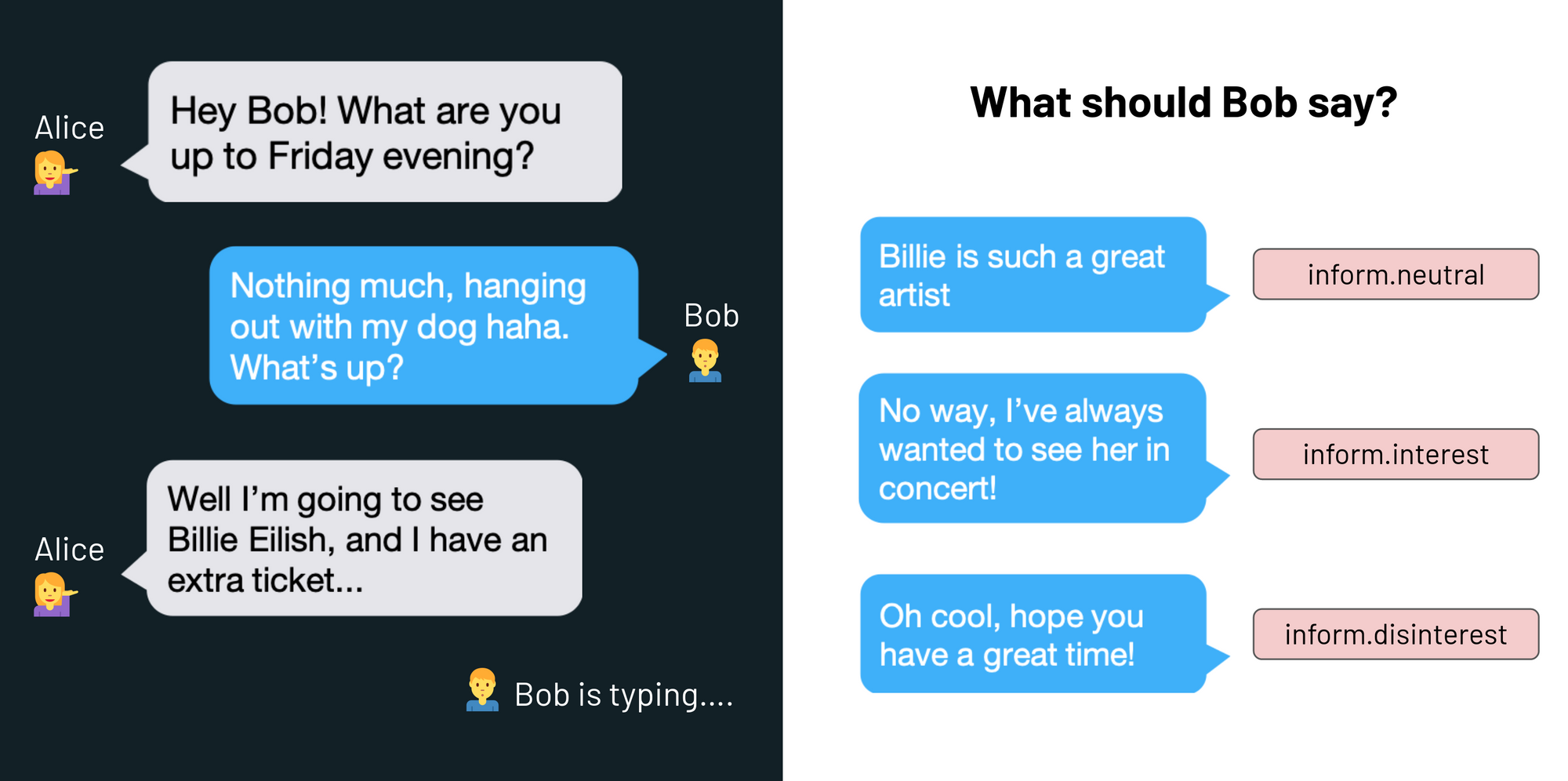
All the possible responses by Bob are valid responses that a language model might generate. These responses correspond to different actions that Bob might take. We want to control language models to generate responses that help Bob achieve his goal, whatever that might be.
Need for Controlling language models
At Cresta, the language model is trained on the real chats of agents, and we find that different agents respond differently to the same situation. We also find that not every agent in a conversation answers perfectly. All this leads to high variance and noise in the training dataset. Thus from this dataset, the model learns a wide distribution of the next possible responses. Since the trained model is more uncertain about the next response, it becomes hard for the model to generate the best response reliably.
In the field of sales, agents use a call-flow which describes what sequence of actions they ideally need to make to get the sale. The best next action for instance could be to ask to close a sale during an appropriate opportunity. To improve the probability of agents making a successful sale, we also want our models to generate a response according to the best next action in that situation. Certainly, a model that generates text that is all over the place won’t suffice.
With our analysis, we also verified that when agents follow the best sequence of actions, it leads to significantly higher sales as shown in the analysis below.

For the chats by expert agents that converted in sales, we see that they largely follow the call-flow. e.d. means edit distance of the real conversation from the call-flow. For example, e.d. of 1 means that the agent deviated by 1 action from the call-flow.

For the chats by all the agents that did not convert in a sale, we see that they deviate strongly from the call-flow.
Instead of relying on training with a maximum likelihood objective to maximize the probability of the next token in the training corpus [1], we want to generate goal-directed responses following a call-flow that maximizes the business metric of sales conversion.
To solve this problem, we designed a controllable language model called “Action-directed GPT-2.”
Action Directed GPT-2
Since we want sales agents to follow a call-flow that defines the best sequence of actions they need to make to make a sale, we also want the suggestions to follow that call-flow.
We break the problem of suggestions following a call-flow into two parts-
- Predict the next best action.
- Generate a good response for that action.
A typical classical dialog state tracking system also follows a similar architecture where it uses a dialog policy to predict the next action and then selects the response based on a template. According to our experience, such a system does not work well because the real-world conversations are too complex to model with a finite number of states. Even if we were to model the states correctly, the text generations from a template would seem robotic and would not be contextually adapted to the current conversation. These reasons lead to low usage of such suggestions by the sales agents.
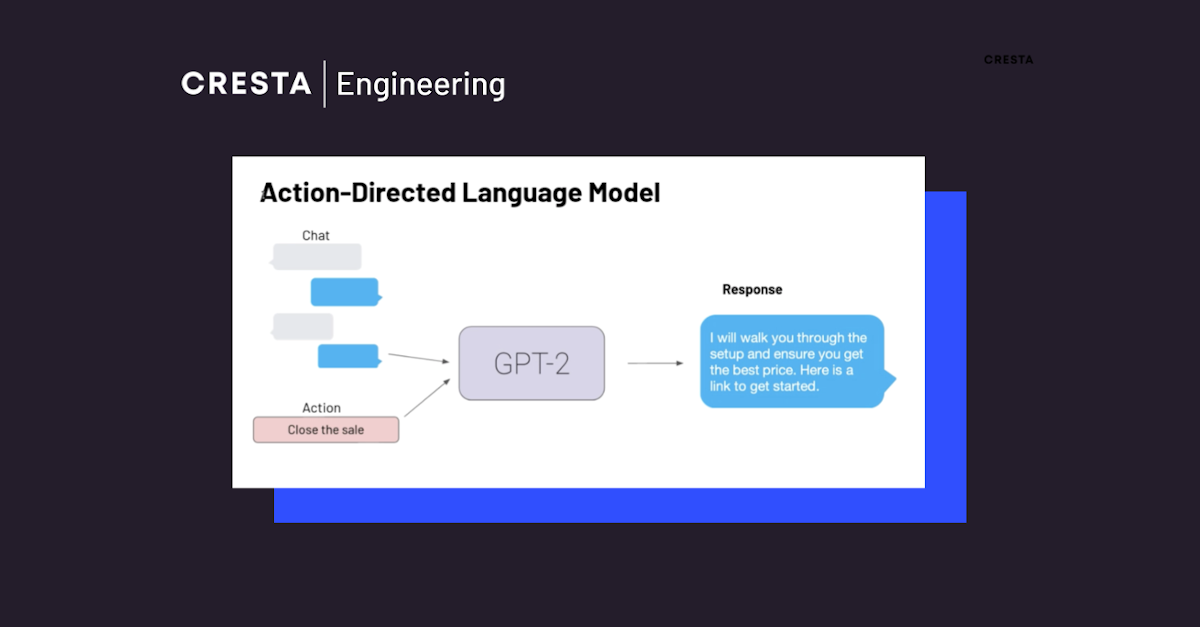
To successfully generate contextually accurate responses that follow the correct next action, we train GPT-2, [2] a large language model, to model the problem as learning the probability of the next response given the current state of the conversation and the next best action. This is represented in the figure below.
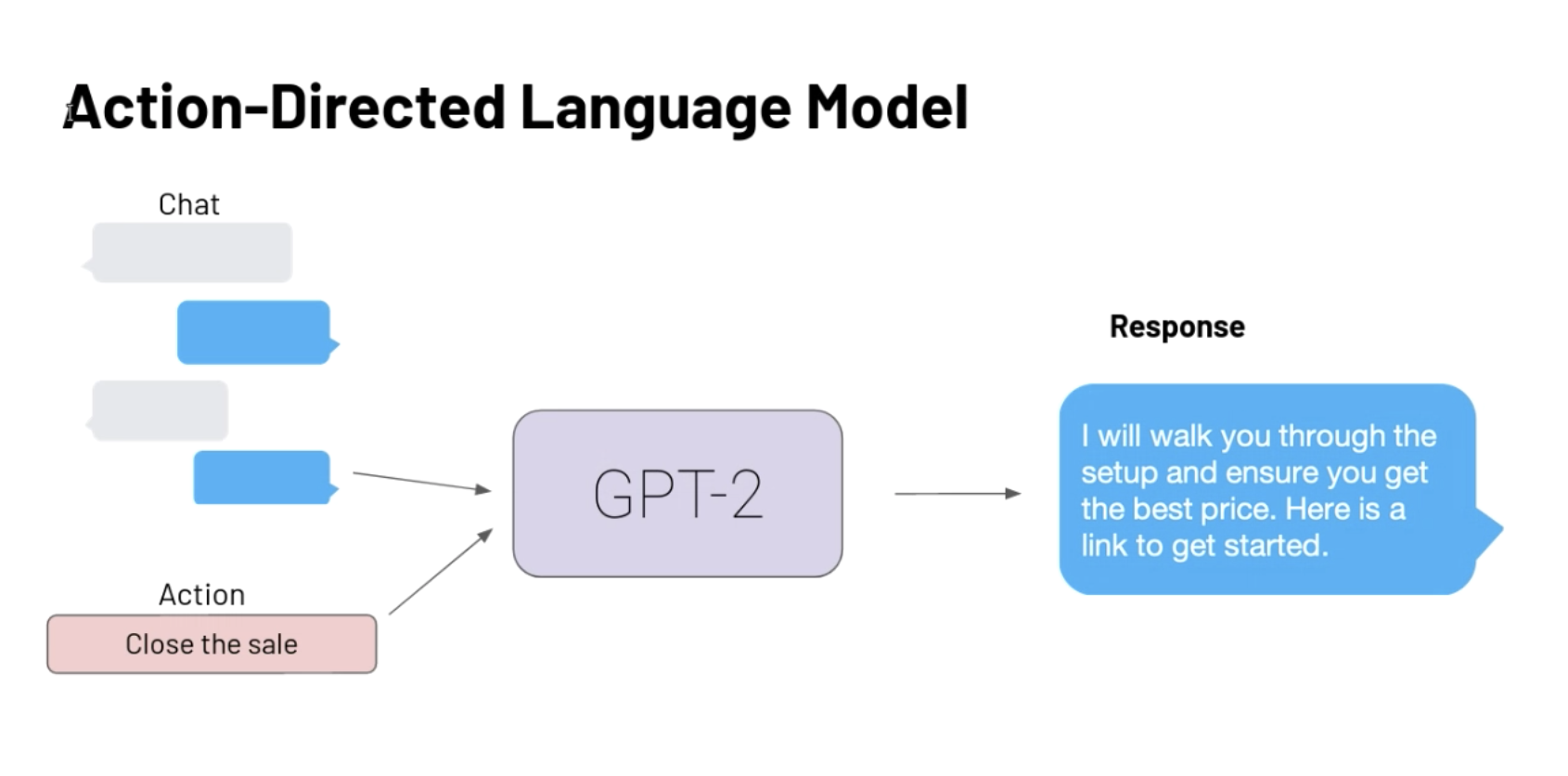
Data representation for Action Directed GPT-2 model
There are multiple possible approaches for feeding the action information to the model. This includes adding an extra embedding layer to GPT2 which learns an action-dependent embedding that represents the action a message performs. Although through experimentation, we discovered that representing actions inline as text resulted in a model that is easier to work with, which also performs very well.
Following is an example of the textual representation on a hypothetical chat with hypothetical actions. Over here, the text in bold is the action label for the following message.
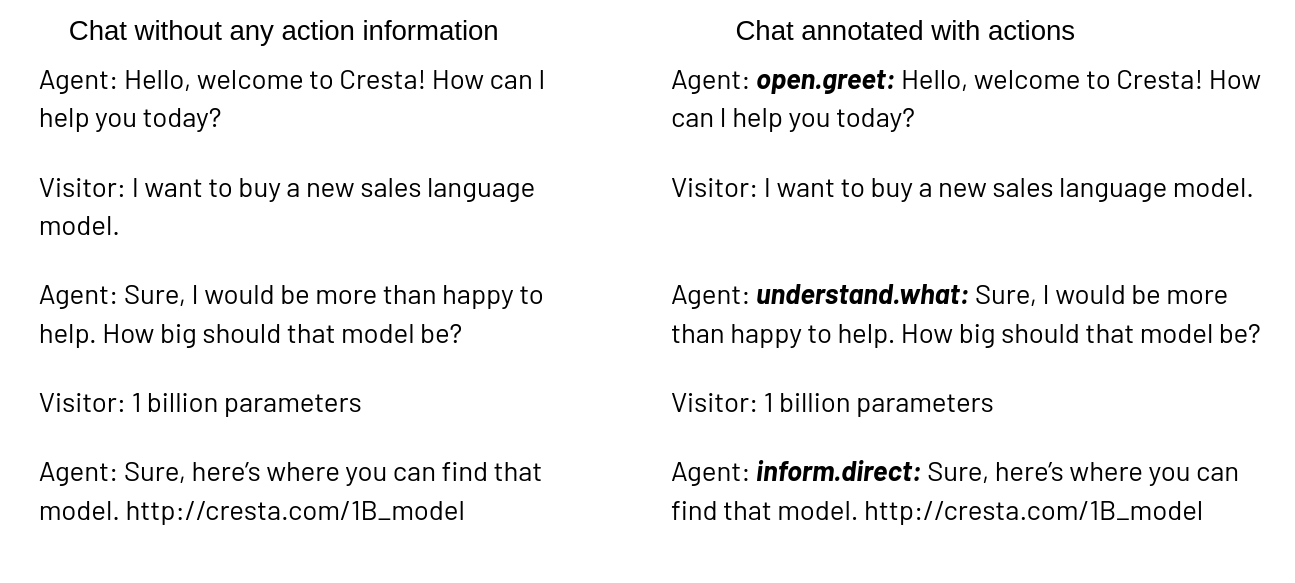
Training and inference
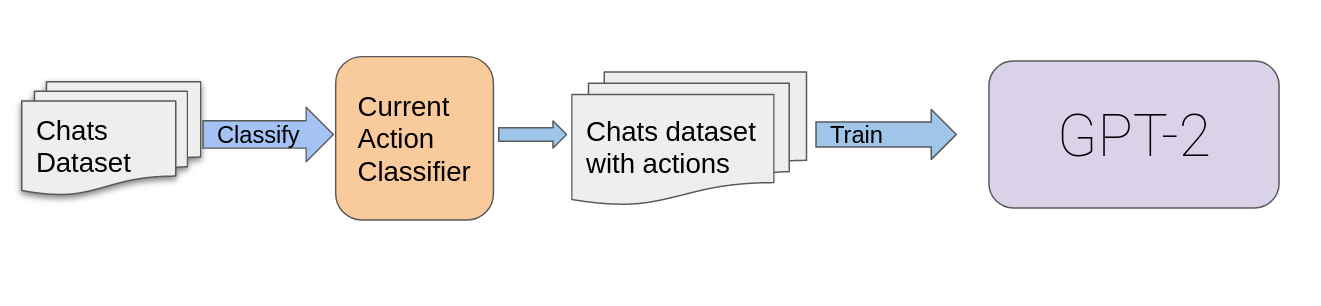
With this representation, we require action labels for messages in the training set and since there can be millions of such messages, it is not feasible to label them manually. We instead use action classification models to label agent messages in the entire training set with their corresponding actions. The messages can also be classified as no action performed, and there is no inline action label for such a case. When all the training set chats are annotated, we use the resulting text representation to train a standard GPT-2 model. GPT-2 being a causal language model, learns to map an action to its associated agent message. Training with a standard language modeling loss function and gradient descent results in the model automatically learning the relationship of the next response to the action and the chat context.
With this trained Action Directed GPT-2 model, given an in-progress chat and next action, we can now generate the next response which would be contextualized and follow the next action. During inference time, we take the current state of the chat, annotate each agent message with its action, take the next best action prediction of the next agent action model and convert it all to a text representation. Once we know the next action to take, there is no significant time penalty during generation so the model also demonstrates high inference performance when deployed. If the next action prediction model does not predict any action, the action directed GPT-2 model falls back to a standard language model generating a response without any action direction.
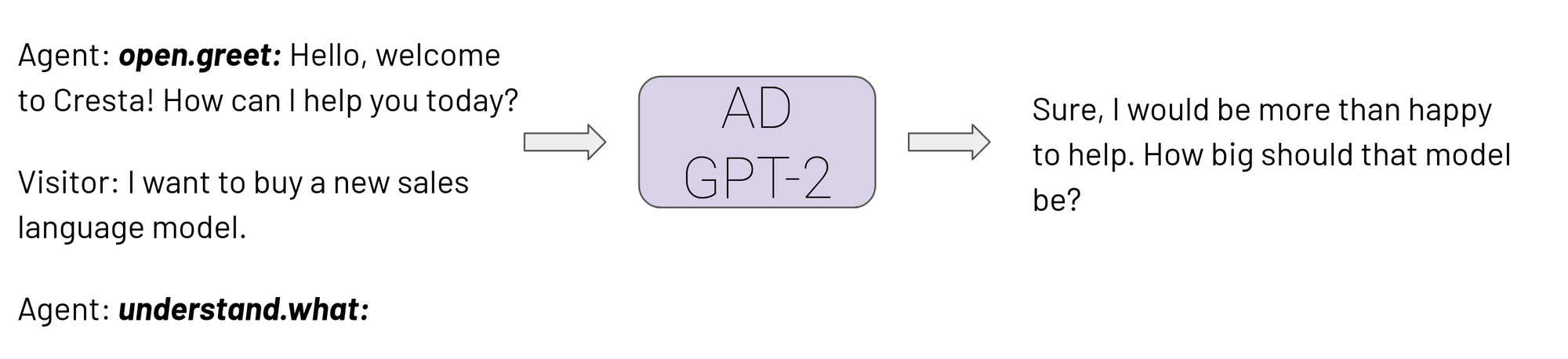
Inference with Action Directed GPT-2
On a test set, we observe that the generations when provided with a model’s prediction of the next best action significantly improves the ability of the model to generate responses that follow the call flow.
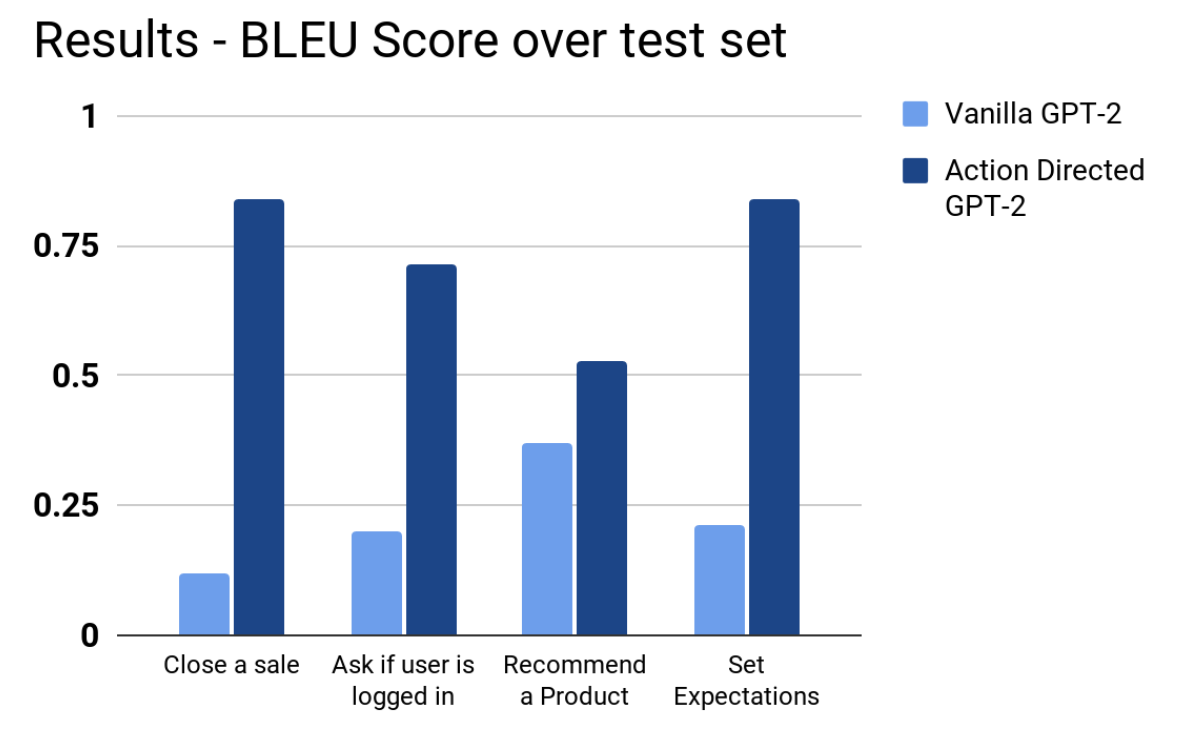
We observe that when provided the next action labels, the Action directed GPT-2 model generates significantly better responses that are on the call-flow. These BLEU scores are measured per action categories.
We also see that the generations by Action Directed GPT-2 follow the next best action whereas Vanilla GPT-2 generations don’t necessarily follow the next best actions and generate suggestions that are all over the place.
After deploying the model to our customers, we found that responses generated by the Action directed GPT-2 help the agents follow the best call flows increasing our customer’s most important sales metrics.

Conclusion
The exciting discovery for us was to discover how simple it is to take an off-the-shelf pre-trained language model and make it controllable without changing anything about the underlying model architecture. If you take a standard pre-trained model and finetune it on a noisy dataset, you can still make the model follow perfect behavior by directing the model correctly during runtime.
Since it is very simple to apply this to any new problems that require action directed controlled language generation, we encourage you to give this model a try with your problems.
Thanks to Jessica Zhao for edit distance analysis and illustrations. Thanks to Tim Shi, Lars Mennen, Motoki Wu, Navjot Matharu for edits and reviews
References
[1] Stiennon, Nisan, et al. “Learning to summarize with human feedback.” Advances in Neural Information Processing Systems 33 (2020). [2] Radford, Alec, et al. “Language models are unsupervised multitask learners” OpenAI (2019)