Contact center agents serve as the vital bridge between consumers and businesses. Beyond just answering queries, they hold the key to seamless interactions, positive experiences, and ultimately, the company’s reputation. Among agents’ core responsibilities, the practice of taking notes (what we call summaries) might seem routine, yet its impact is anything but ordinary.
Consider the diverse array of information exchanged during customer-agent conversations: from intricate technical details to specific needs and concerns. These interactions contain important pieces of information that are unique to customer’s business and operations. After-call notes must strip away irrelevant details and distill the essence of the conversation.
However, the scope of these notes reaches further. They serve as liaison points between departments. For instance, a customer’s shipment complaint might start in the contact center but involve logistics. Detailed notes ensure a seamless transition, showcasing the company’s commitment to coherent and efficient customer care.
The significance of agent notes transcends even these functions. They’re invaluable for coaching, reviews, and compliance adherence. By documenting interactions, agents create a history that aids personal growth and allows supervisors to provide targeted feedback. In regulated industries, these notes exemplify adherence to standards and underline transparent service.
In the race for efficient customer service, every moment counts. But after-call work such as note-taking can add another 20% or more to a call once it’s over, driving average handle time (AHT) up and requiring an agent to dedicate extra time before moving on to another call, while pulling their focus from what truly matters – delivering interactions that drive exceptional customer experience and support the business’ bottom line.
The strong summarization capability of LLMs is unparalleled
One of the most remarkable abilities in large language models (LLMs) is to distill extensive and complex information into concise, coherent, and meaningful summaries. Unlike traditional methods that often require manual effort and human subjectivity, LLMs harness the power of machine learning to autonomously identify the core ideas, key points, and essential details within a text. This capacity to summarize content efficiently and effectively holds immense potential across various domains, from aiding researchers in comprehending vast amounts of literature to enhancing productivity by condensing lengthy reports.
In the academic and research community, the emergence of LLMs has claimed to have solved the summarization problem. For enterprises, the availability of OpenAI GPT3.5, Anthropic Claude 2, etc., makes summarization commoditized.
Why contact centers need more than just generic summaries
As we previously discussed in “Emerging stack of generative AI”, LLMs ≠ AI System ≠ AI Product. LLMs provide the powerful technical foundation for solving the problem, but to truly drive business impact, you need an AI product that is customized for business use cases and seamlessly embedded into agent workflows.

Generic foundation models are trained on open internet data, thus excelling in generating generic summaries that are coherent and well-written.
However, to further customize LLMs’ output, prompting is undeniably valuable for tailoring responses to specific queries or tasks. But it has its limitations when it comes to altering output topics, style, and terminologies.
- Firstly, while prompts can steer the model in a particular direction, they often struggle to produce content on entirely new or obscure subjects. The model’s knowledge is grounded in pre-existing data, and it can only generate information it has been trained on.
- Secondly, changing the writing style can be challenging because the model tends to default to a consistent tone and vocabulary. It may require extensive iterations to achieve a desired style, which can be time-consuming.
- Lastly, manipulating terminologies can be tricky, as the model tends to stick to conventional language and might not readily adapt to industry-specific jargon or creative language choices.
The recent rollout of GPT3.5 fine-tuning from OpenAI largely states the necessity and demand of business customization and model finetuning.
Cresta Auto Summarization goes beyond ChatGPT for Contact Center
Our approach
While many in the industry rely on generalized summarization, we’ve developed a unique approach based on our discussions with field leaders and frontline agents which hinges on key points like:
- Contact center interactions often involve highly specialized knowledge and jargon specific to particular industries or domains.
- Contact center after-call work, where auto summarization will be used, demands efficiency and standardization. This puts higher requirements on latency and output summary consistency.
- Feedback to summarization is difficult to incorporate into the model through prompt engineering.
At Cresta, we are building the “Specialist,” creating LLM tailored to individual sectors and specific tasks. This guarantees that vital information in these interactions, often laden with industry-specific nuances, is accurately condensed, providing invaluable support for agents and enhancing overall customer service efficiency.
Our unique fine-tuning approach, leveraging Ocean-1 and domain knowledge, ensures consistent delivery of summary notes with low latency that are compliant with customer’s notation “templates.”
A feedback loop through auto-training makes sure agent edits and curations are used to update the model regularly through supervised fine-tuning and RLHF.

Overall Architecture
Tailored format, topics, phrases, and terminologies
The final goal for automated call/chat notes is reducing time spent on after-call work and enabling agents to fully focus on customers during the call.
However, while we use the word “automated” often, the reality is, human interactions are still very present in the full workflow. We shouldn’t expect AI to do the job 100% and call it a day—agents will still need to occasionally edit, validate, or approve the auto summary generated. This means that, the more familiar auto generated notes feel to their daily verbatim, the faster the human-in-the-loop process is. That’s why a tailored model is critical here; to that end, Cresta takes a three-step approach:
- First, Cresta is able to generate summaries in formats that align seamlessly with the reading, writing, and editing preferences of contact center agents, ensuring a familiar and efficient workflow.
- Second, our model distills conversations into only the most crucial topics related to the business, streamlining the information overload that often plagues customer interactions and thereby enhancing overall efficiency.
- Third, we offer standardization and maintain a consistent format throughout summaries to ensure that every piece of information is presented in a uniform and easily digestible manner, facilitating better cross-functional communication and collaboration within the organization.

The above table illustrates a comparison between raw gpt-3.5-turbo, agent notes, and Cresta summary. Our summary aligns with agent notes, capturing business-critical entities like resolution, using domain jargon like BOGO (buy one get one) and teaser rate, and offering customized templates and structure.
Inference Scalability and Stability
Businesses craving efficiency in their contact center understand the value of agents finishing their after-call work (ACW) in a relatively short time. With auto summarization, some organizations have achieved ACW as low as 30 seconds. A prolonged latency which requires agents to wait for summaries to be generated puts operational efficiency at risk and causes undue stress for agents.
Thanks to our model fine-tuning and dedicated serving infrastructure, we are able to serve much smaller models with comparable quality but with 5x or more latency improvement.
Below is ~1 week measurement for ChatGPT Summarization model vs In-house Summarization model
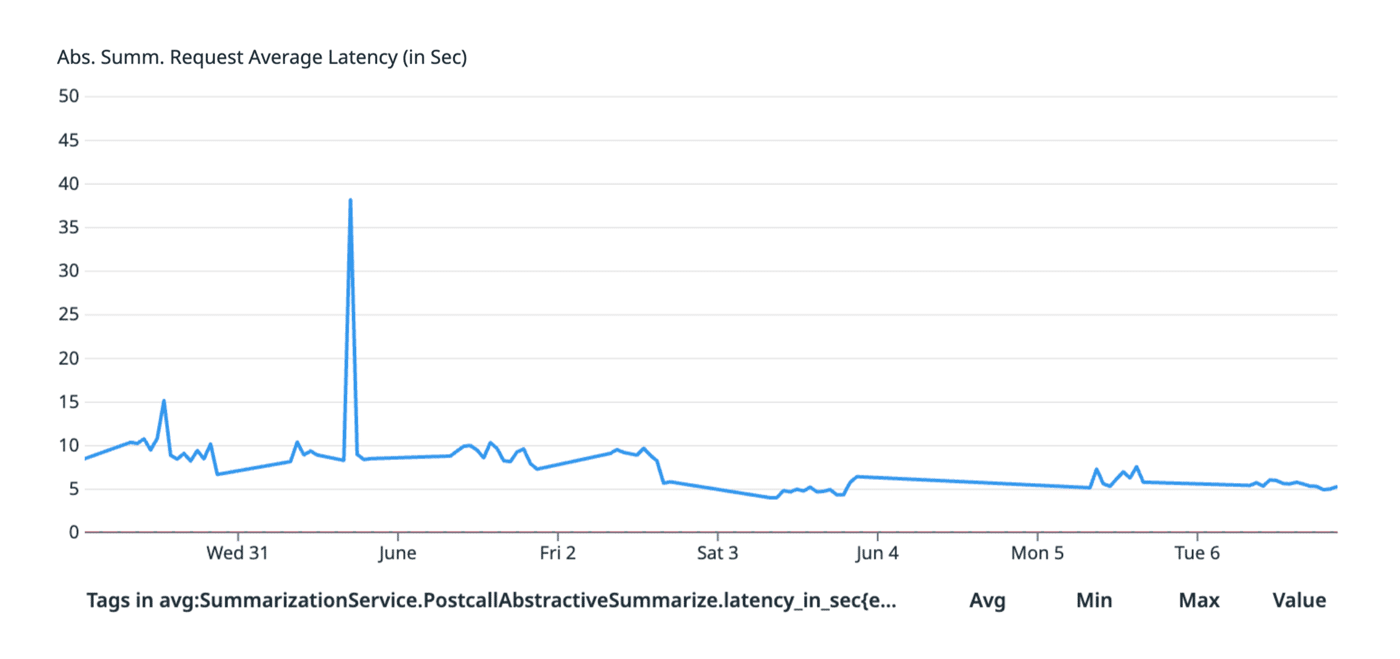
ChatGPT Summarization model
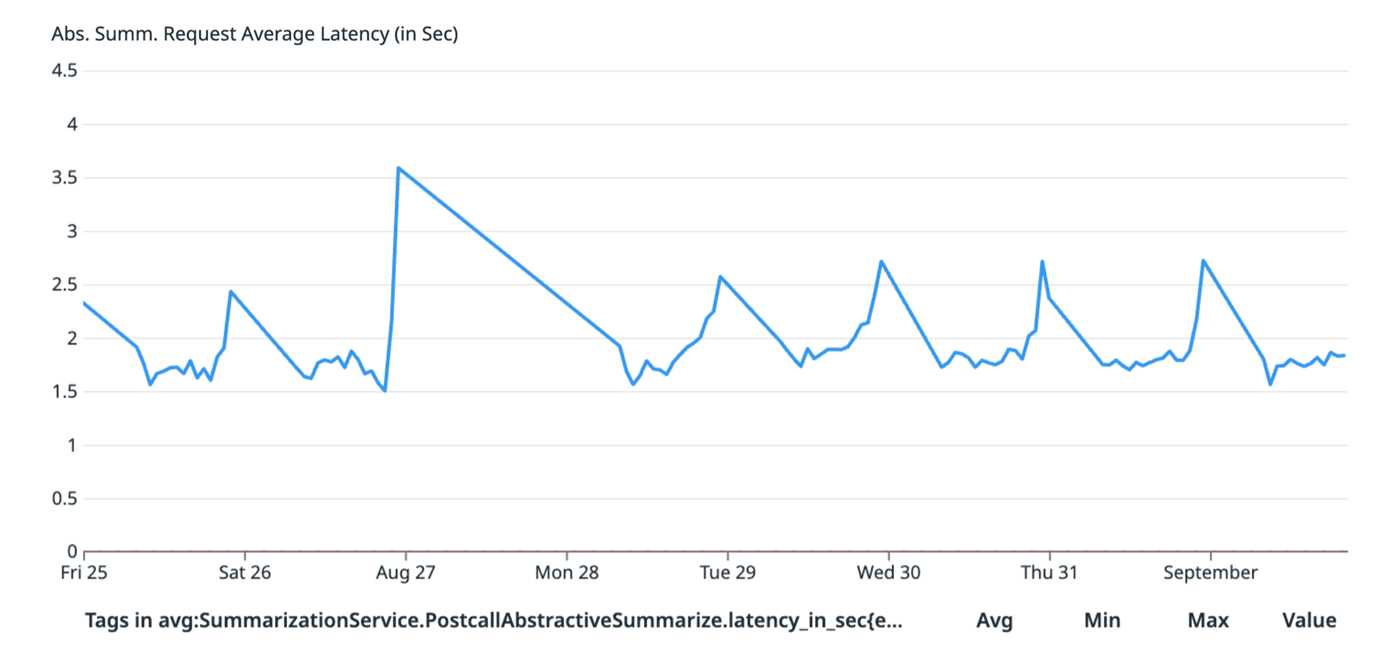
In-house Summarization model
What’s more, our serving infrastructure supports large batch post-call processing jobs with high throughput, where in LLM API provider cases (OpenAI), organizations will need dedicated instances to increase prediction volume processing large volumes of data could be time-consuming.
Feedback Loop
Cresta auto summarization is automatically improved with agent usage. While a feedback loop through prompt engineering often involves many rounds of back-and-force iteration and testing, agent edits and curation naturally create the feedback loop data for model fine-tuning and RLHF. Plus this process is done automatically through our auto training/evaluation/deployment infrastructure, reducing the need for involving prompts of each customer which is likely unscalable.
Success Stories and Typical Impact:
Across our customers, we’ve seen that on roughly 80% calls, auto summarization saves 1 minute of typing time, while saving more time when calls are longer.

Conclusion:
As contact centers increasingly prioritize efficiency and look for opportunities to leverage generative AI to drive down average handle time, innovations like Cresta’s auto summarization will prove vital competitive differentiators. Schedule some time to learn more today!