In the early days of conversational AI, testing and evaluation were fairly predictable. Flow-based bots followed strict, pre-defined paths, so teams could simply simulate each step and confirm that every interaction point returned the expected output. Evaluation focused on whether the final outcome matched the script. These processes were deterministic: if you entered the same input, you always got the same output.
With the shift to LLM-first AI agents, that predictability disappears. Large Language Models (LLMs) introduce non-determinism, meaning the same input can generate an infinite number of responses, many of which could be valid (even with temperature set to 0!).
This makes AI agents far more natural and capable–but it also breaks the assumptions that traditional testing and evaluation rely on.
This post is part of our ongoing series on non-deterministic testing and evaluation for AI agents. It follows our recent announcement of new enhancements to the Automated AI Agent Testing suite, which introduced tools designed to help enterprises deploy AI agents more safely and efficiently.
Why deterministic frameworks fail at scale
There's a reason these old testing methods were never applied to human agent conversations: the level of variance in real-world interactions made it infeasible. The same challenge now applies to modern LLM-based agents, which engage in natural, freeform conversations that can’t be accurately evaluated using frameworks built for flow-based bots.
Every small change to a flow or prompt triggers a cascade of manual updates. Scripted tests and expected results must be rewritten for each turn of a conversation, aligned to new customer phrasing or edge cases, and revalidated to stay accurate. Since LLMs can produce valid variations of a response, even correct answers can break rigid scripts, creating false failures and wasted effort. Multiply this by thousands of conversations, and the testing and evaluation process quickly becomes slow, resource-intensive, and misleading, preventing teams from improving quality at scale. Counterintuitively, even a single successful test run can prove insufficient - run the test again and it could fail!
Take a simple example: a customer needs to reset a device. There might be several ways to do it, such as unplugging and plugging it back in, or pressing and holding the reset button. The AI agent could choose either method first and still be correct, but a turn-by-turn deterministic test might flag one as a failure simply because it didn’t follow a pre-defined order. This rigidity makes it nearly impossible to evaluate agents under real-world conditions, where multiple valid paths can lead to the same successful outcome and language and user behavior constantly vary.
The move toward goal-driven evaluation
The first major step toward solving this problem was goal-driven evaluation, measuring whether the AI agent accomplished the customer’s intended outcome rather than matching exact responses. For example:
- Did the AI agent use the right APIs?
- Was the issue resolved by the end of the conversation?
To enable this, simulation became a core testing method. By simulating realistic user goals and conditions, evaluators could measure whether the AI agent achieved the desired result without manually scripting every turn. However, goal-driven evaluation also revealed several major limitations:
1. Surface-level accuracy: Confirms whether the goal was met, but not how.
Sycophancy and false success: One common failure pattern occurs when LLMs become overly agreeable, a behavior often referred to as sycophancy. In these cases, the agent might appear to produce a correct answer by echoing the customer’s assumptions or confirming incorrect statements, rather than genuinely reasoning through the task. In testing, this can create the illusion of success. For example, an AI agent might tell a customer their account issue is resolved simply because the customer insists it is, even though the agent never confirmed the fix in the system. In a goal-driven simulation, this may appear as a ‘pass’ even though the task was never actually completed.
Conversation clarity gaps: Another frequent issue is when agents reach a correct outcome through confusing or incomplete exchanges. In testing, this happens when an agent technically accomplishes the goal but does so in a way that would frustrate or confuse a real customer. For example, an AI agent might successfully book a flight, but get caught in a loop of repeated confirmations or skip key verification steps. These outcomes technically meet the goal, but the quality of the experience fails human review.
2. Low diagnostic value: When a failure occurs, it’s hard to pinpoint why.
Did the agent misunderstand a step? Did the simulated visitor behave unrealistically? Or were there multiple issues compounding the failure? For example, if an AI agent fails to help a customer reset an alarm, it can be unclear whether it forgot to ask them to reset their WiFi or failed to prompt them to check the battery. And when several breakdowns occur at once, it becomes difficult to understand the full scope of what went wrong. You know it failed, but not where or why.
3. Unrealistic simulations
Even with sophisticated modeling, simulated testing environments often fail to fully represent real-world customer behavior. LLMs—and even human testers—don’t always act like real customers, making it difficult to ensure that test scenarios mirror the conversations agents face in production.
Toward a broader testing and evaluation framework
To properly assess modern AI agents, teams need to go beyond simple goal success or failure. A layered approach that combines multiple testing and evaluation types ensures coverage across functionality, conversation quality, and real-world variability.
| Testing Methods | |
| Static Replays conversations to measure consistency and regression. |
Dynamic Simulates user behavior through generated interactions. |
| Full conversation testing: Uses real historical or test conversations as fixed inputs to verify behavior remains stable across agent updates | Simulated customer testing: Uses an LLM-based customer that follows a goal or instruction (e.g., booking a flight) under varied conditions, exposing real-world unpredictability and helping identify how the agent handles edge cases |
| Interaction points (Snapshot) testing: Captures a moment in context (e.g., when the AI agent gave an incorrect or best-practice response) for regression testing, ensuring that specific behaviors remain consistent after updates | |
| Frequency: Take a pass^k approach, re-running critical tests multiple times to ensure consistent performance (rather than taking a single success as sufficient) | |
| Evaluation | |||
| Evaluation methods | Deterministic evaluation: Uses logic checks like verifying successful API calls, accurate data retrieval, or completion of compliance steps to confirm that the agent behaved as expected | Expert-aligned LLM judge evaluation: Employs calibrated LLM evaluators to assess nuanced behaviors, such as flow adherence, response relevance, or factuality | Manual human review: Involves experts validating edge cases, refining evaluator calibration, and ensuring that LLM-based assessments align with enterprise quality standards |
| Evaluation scope | Turn-based: Ensures an action occurs at a specific moment in the conversation (e.g., reading a disclosure immediately after collecting payment information) | ||
| Conversation- or phase-based: Evaluates whether goals are met over an entire flow or interaction section (e.g., verify whether the AI agent successfully completed the entire payment flow—from authentication to confirmation—while maintaining compliance throughout) | |||
By combining these layers, teams can measure both what the agent achieved and how it performed across realistic, varied conditions.
Just as important as choosing the right methods is knowing when to use them. Each approach delivers unique value at specific stages of development and deployment - a topic we’ll explore further in an upcoming post focusing on timing, learnings, and best practices from Cresta’s testing journey.
How this comes together in production
Human conversations—whether between customers and human agents or between customers and AI agents assisting them—are inherently variable and context-driven. Recognizing this, we’ve applied lessons from years of refining human agent quality management to the way we test and evaluate AI agents. Like human agents, today’s LLM-powered agents must be assessed for both correctness and quality across dynamic, real-world conditions.
Our Automated AI Agent Testing suite builds on that foundation, helping enterprises deploy AI agents faster and with greater confidence. Rather than treating each test type as a separate effort, our approach unifies static, dynamic, deterministic, and non-deterministic approaches into a workflow that mirrors production performance.
Built on real conversations: We use real historical conversations (whether with human or AI agents, or created during testing) to capture both erroneous and “golden” interactions. These become the basis of static tests and inputs for dynamic testing.

Flexible evaluation layers: Modular, reusable evaluators let teams assess AI agents with:
- Logic-based (deterministic) checks for precise rules (e.g., keyword or regular expression matching, correct article retrieval, expected action) to ensure the right data is accessed and the correct behavior is performed at the turn or conversation level.
- LLM judges that are fully aligned, calibrated and validated against expert consensus and informed by Cresta's deep contact center experience. These expert-aligned judges reflect enterprise standards for nuanced evaluations (e.g., Hallucination Detection, Golden Response, Flow Adherence) across the conversation.

Simulation at scale: Cresta’s AI-powered Simulated Visitor replicates realistic customer behaviors, goal-seeking logic, and conversation flows. This stress-tests agents and exposes weaknesses before deployment, helping teams test for both expected and unexpected conditions.
We’re continuously investing in making these simulations more representative of real-world scenarios. By mining historical conversations across both human and AI agent interactions, we can model authentic user behaviors, edge cases, and dialogue patterns. This capability—enabled by Cresta’s unique platform that combines human and AI agent data—feeds back into simulations, creating a continuously improving testing ecosystem that reflects how customers actually communicate.
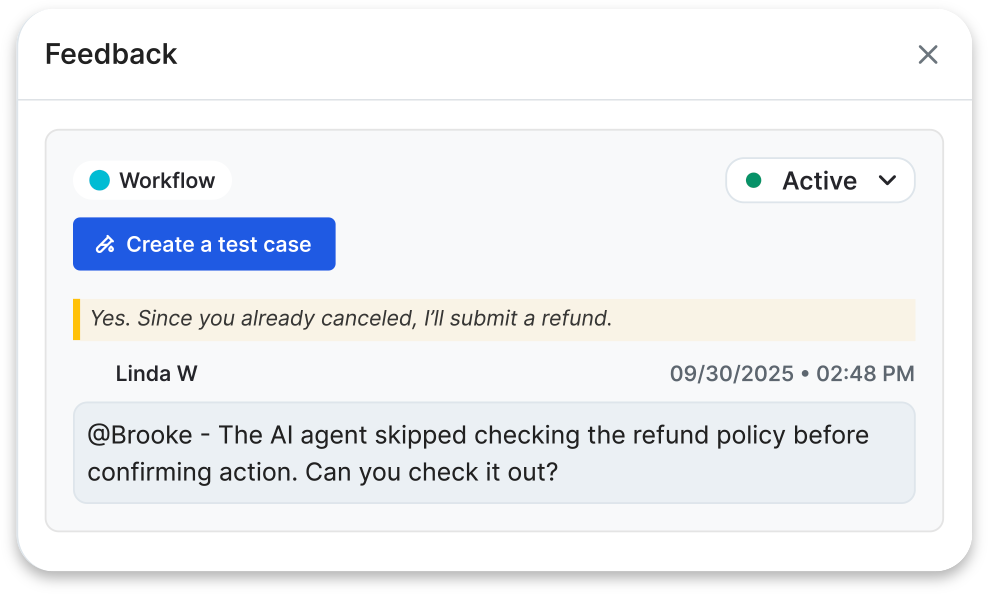
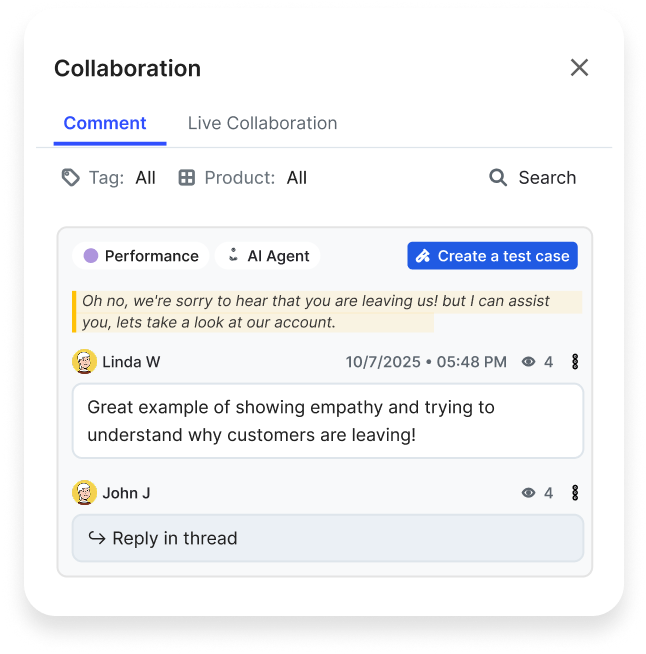
Human in the loop: Manual review and annotation remain core to our process, aligning automated evaluations with expert expectations. Teams can flag issues directly in real AI Agent conversations and instantly convert them into test cases, closing the loop between feedback and testing.
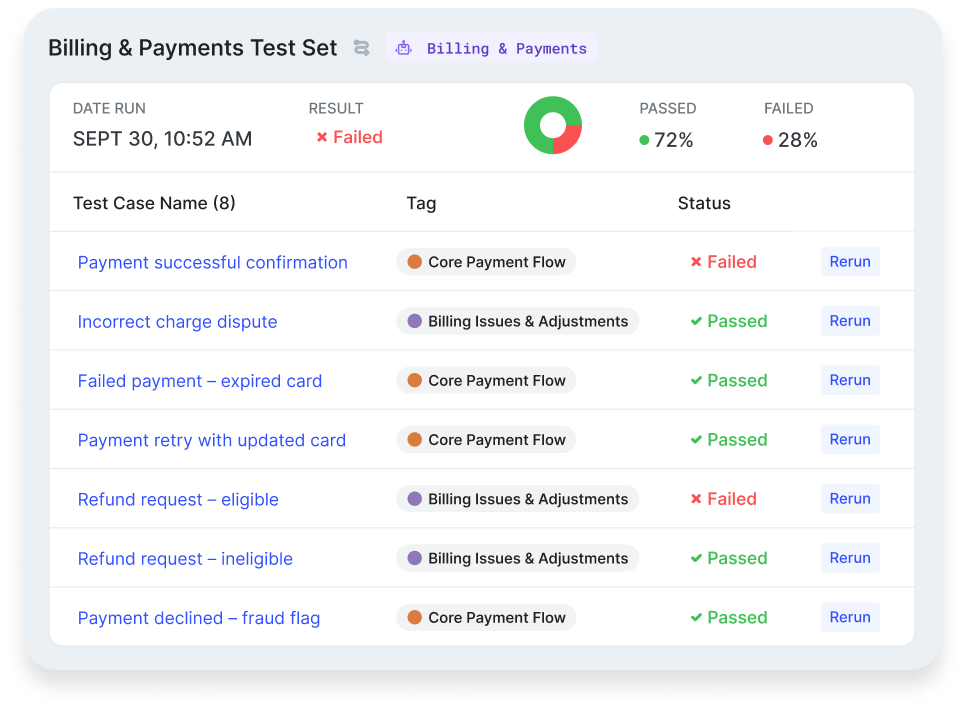
Continuous validation: Once automated test runs are set up, they can be easily re-run with each AI agent iteration, ensuring efficiency without sacrificing quality.
This blended approach brings scalability, precision, and transparency to every stage of AI agent development and deployment, making it easier for Cresta customers to iterate confidently and deliver enterprise-grade reliability.