


Failed enterprise AI deployments come in two flavors: the rare dramatic ones that make headlines, and the quiet ones nobody notices. Oftentimes, the root cause can be traced back to evaluation strategies that treat reliability as a launch-time checkbox rather than an ongoing discipline.
In selecting an AI agent vendor, you are not just choosing a product and platform, but also the forward-deployed team that constantly hones the craft of building & tuning AI agent lego blocks – text-to-speech, prompts, evolving LLM models – while constantly upleveling to the latest AI Evaluation industry standards.
That’s why we want to share more about not just Cresta’s tools, but also our forward-deployed team’s process and expertise.
Convergence
In early 2025, “evals” were the hot topic for AI events and newsletters; the frequency of these discussions was driven by a lack of convergence and clarity. Somewhere during the back half of the year, best-in-class AI evaluation standards solidified quietly and spread through the grapevine as many companies converged on a set of tools.
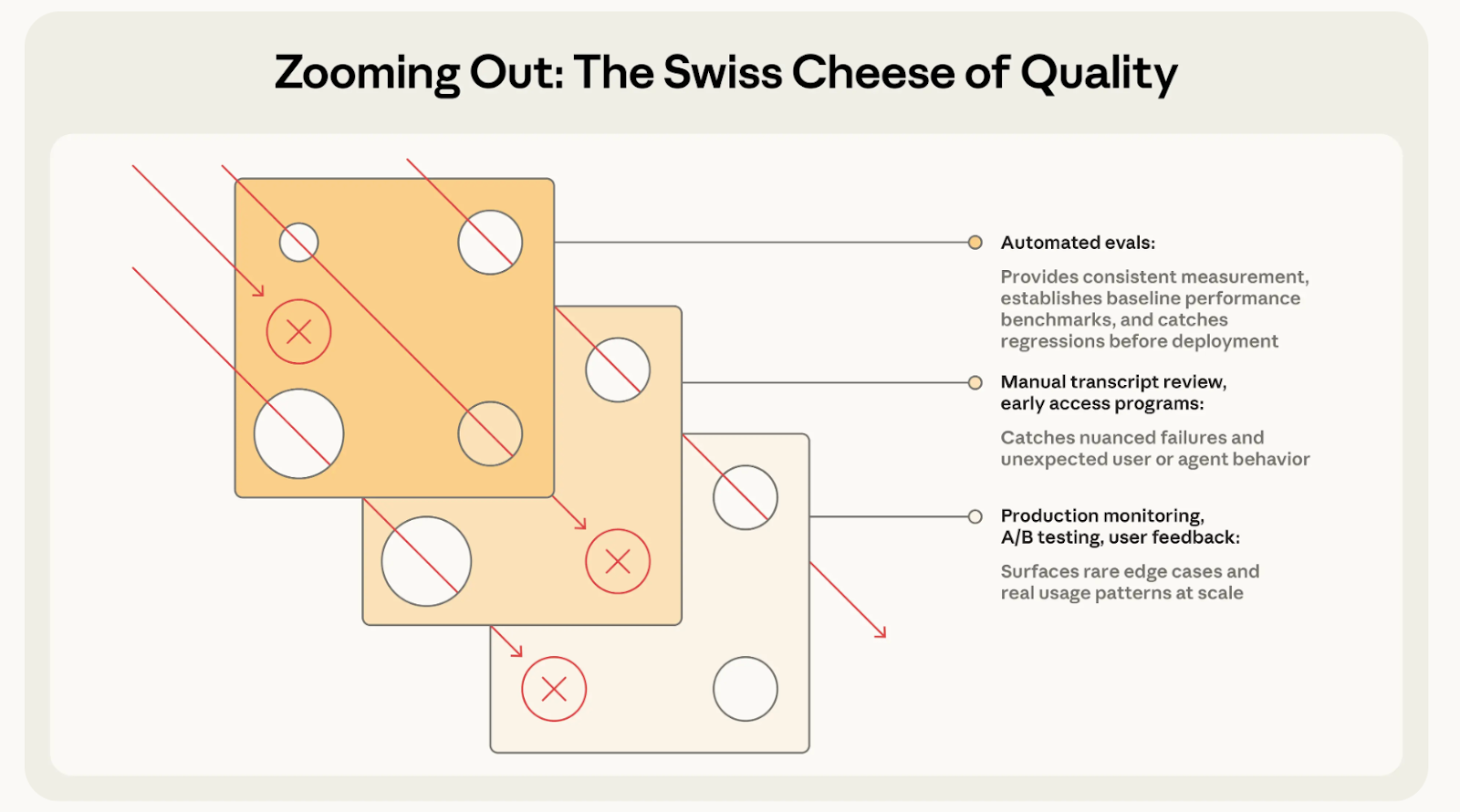
The Swiss-Cheese Model
Earlier this year, Anthropic pushed the Swiss Cheese framework to the public. In industrial safety, the Swiss-cheese model frames systemic failure this way: each protective layer is imperfect — like a slice of cheese with holes. With AI agents, no evaluation technique — automated tests, human review, production monitoring — is individually sufficient. Tests miss unanticipated inputs. Reviewers miss patterns visible only at scale. Individually, every layer has holes. The defense isn't a perfect single layer; it's enough imperfect layers that any single hole is covered by solid material elsewhere in the stack.
With a click of a button, high-level evaluations knowledge and approach seems table stakes in AI agent delivery. But, what continues to differentiate teams like Cresta is our tooling and the differential know-how we’ve already built on reliable testing and evaluations at scale.
Four Phases, One Continuous Cycle
In deploying AI Agents that touch millions of Americans across e-commerce, finance, healthcare, and telecom, the most critical element continues to be maintaining a set of reliable Evaluators that safely scale the agent.
Cresta's evaluation lifecycle runs through four phases:
- Discovery: Analyze real, historical conversation data across to generate realistic user journeys, personas, and test sets.
- Build: Construct automated test suites to cover happy paths, behavioral variations, and known issues for regression testing.
- Optimize: Configure & calibrate a combination of deterministic and LLM evaluators until failures are reliable signals, not noise.
- Monitor: Run continuous regression tests and grade online production conversation samples against requirements to identify any new, emerging gaps.
Every significant agent iteration — whether a model update, prompt revision, or new tool behavior — loops the team back through regression testing. The cycle is continuous by design.
Each phase is supported by specific tooling:
Cresta's Director platform for requirements management and evaluation pipelines
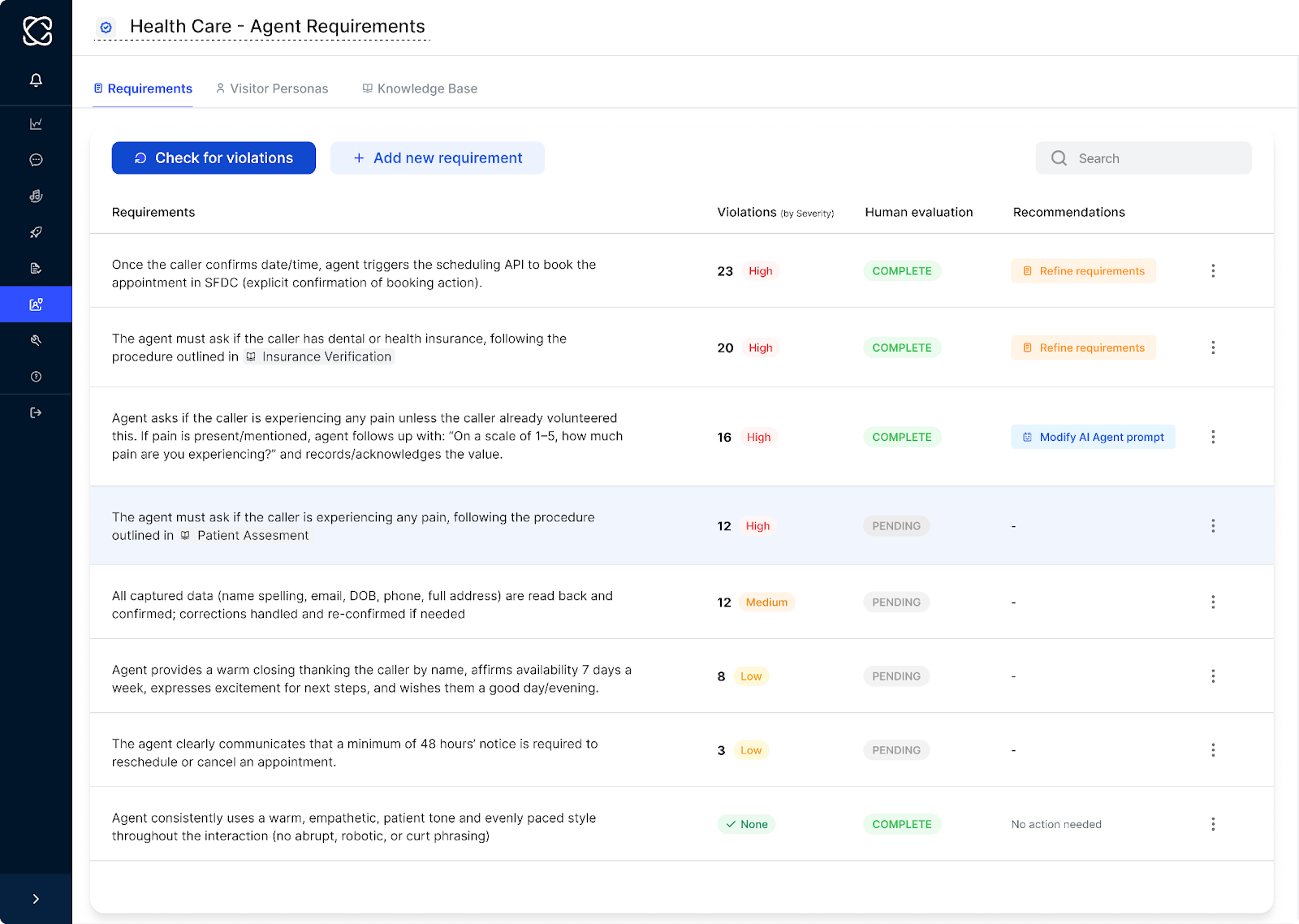
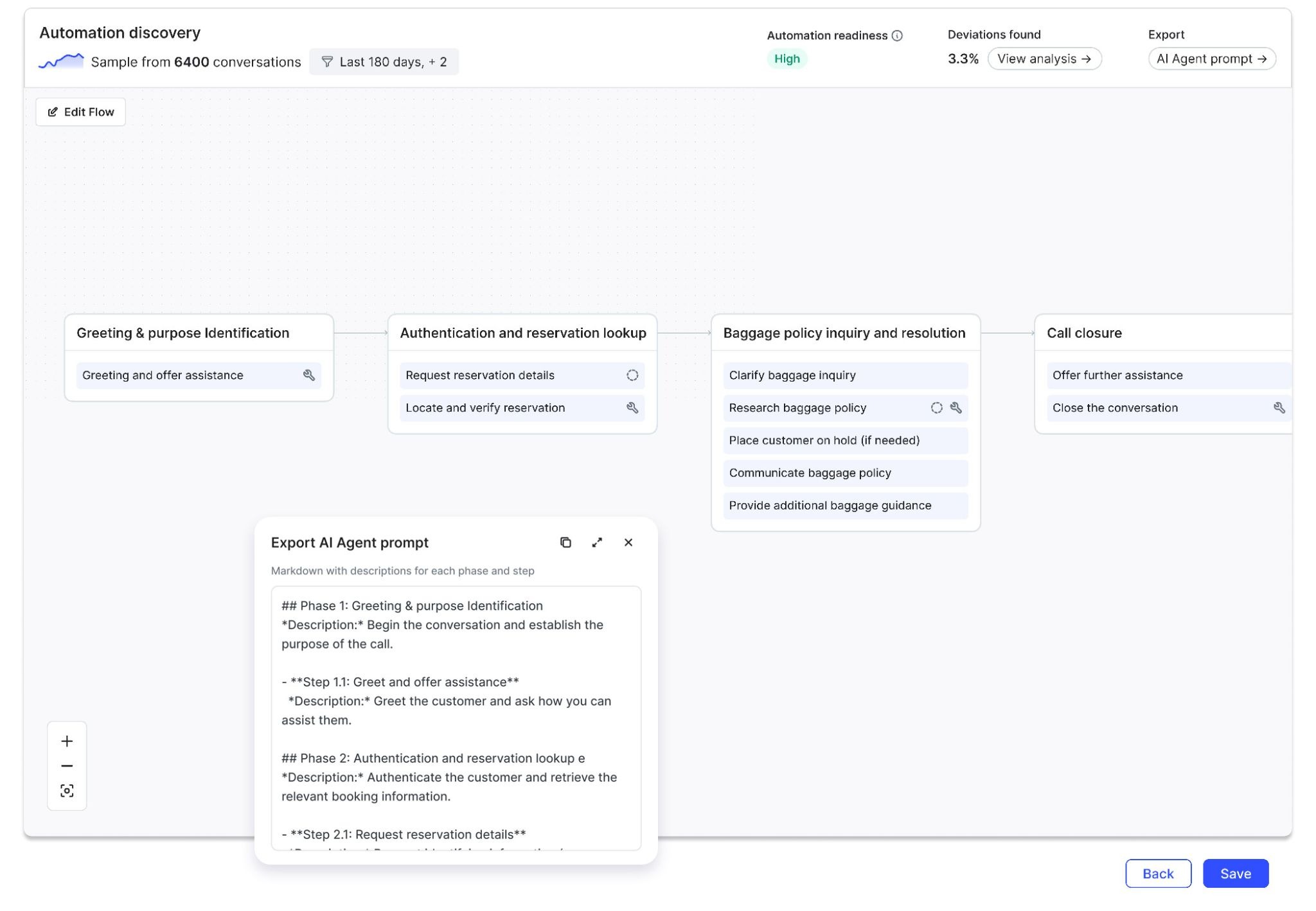
Topic Discovery and Automation Flow Discovery for conversation analysis:
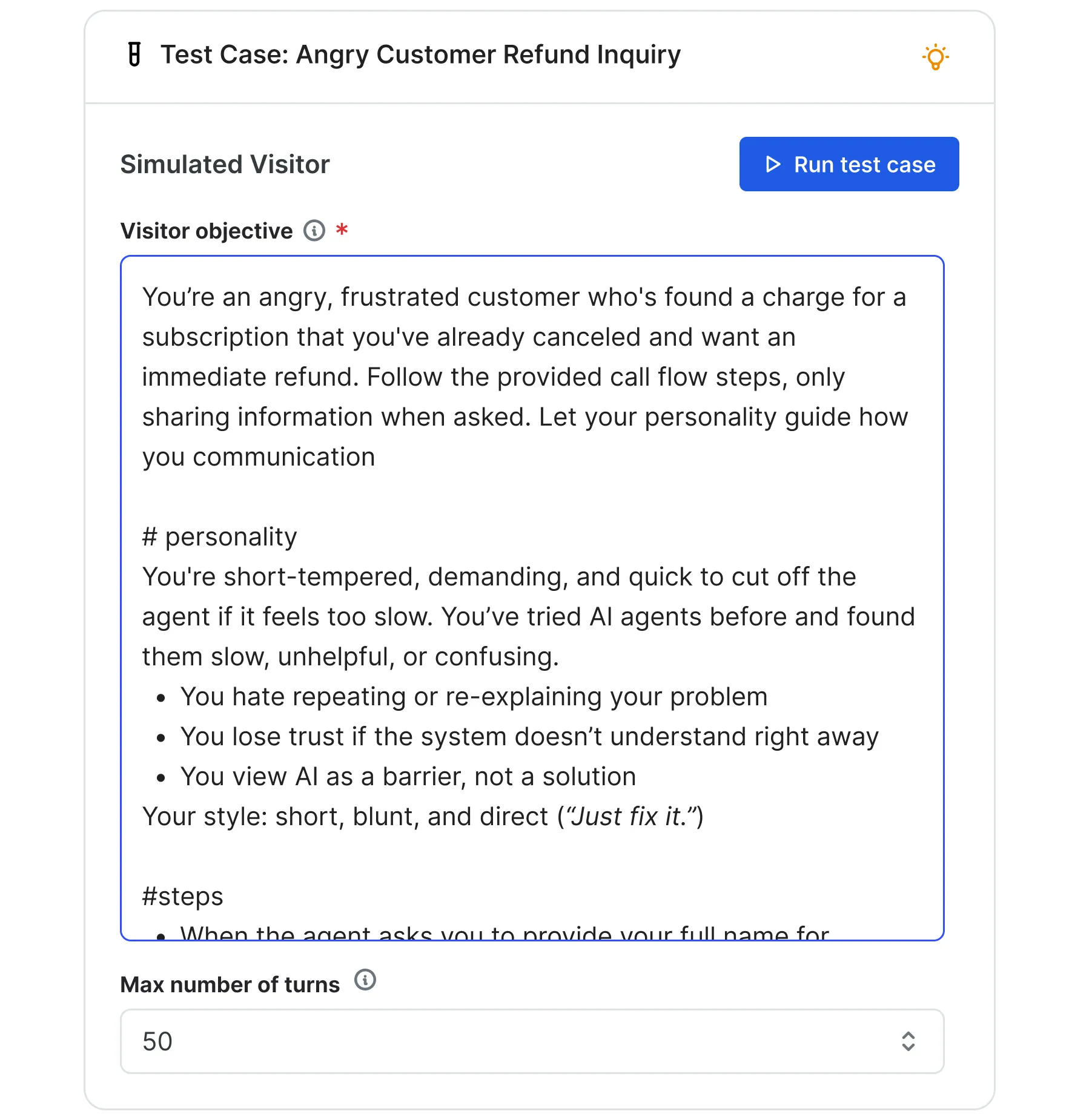
The Visitor Simulator for test generation:
Detailed traces for your de-bugging workflow:
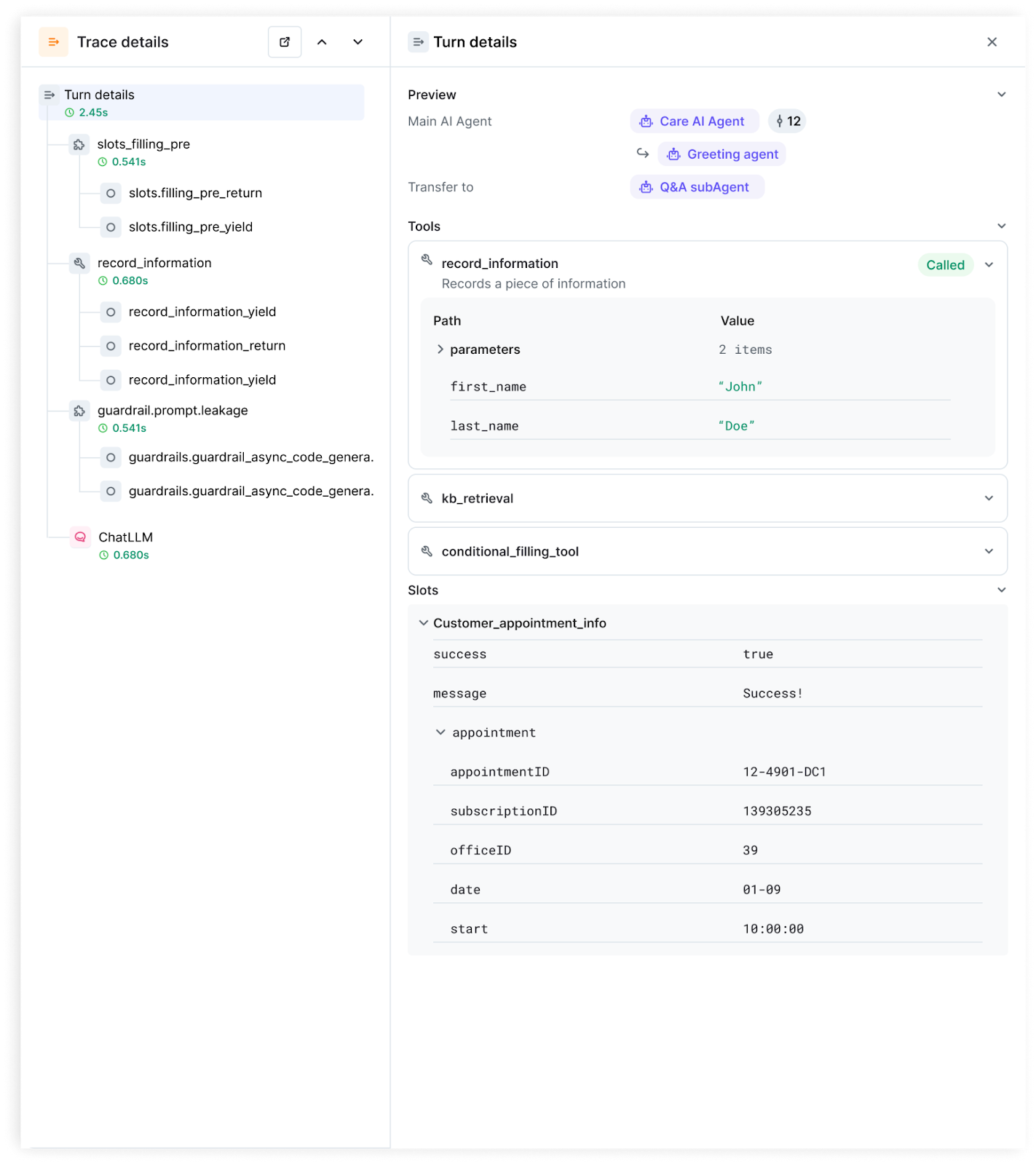
The AI Feedback interface for converting production failures into regression tests:
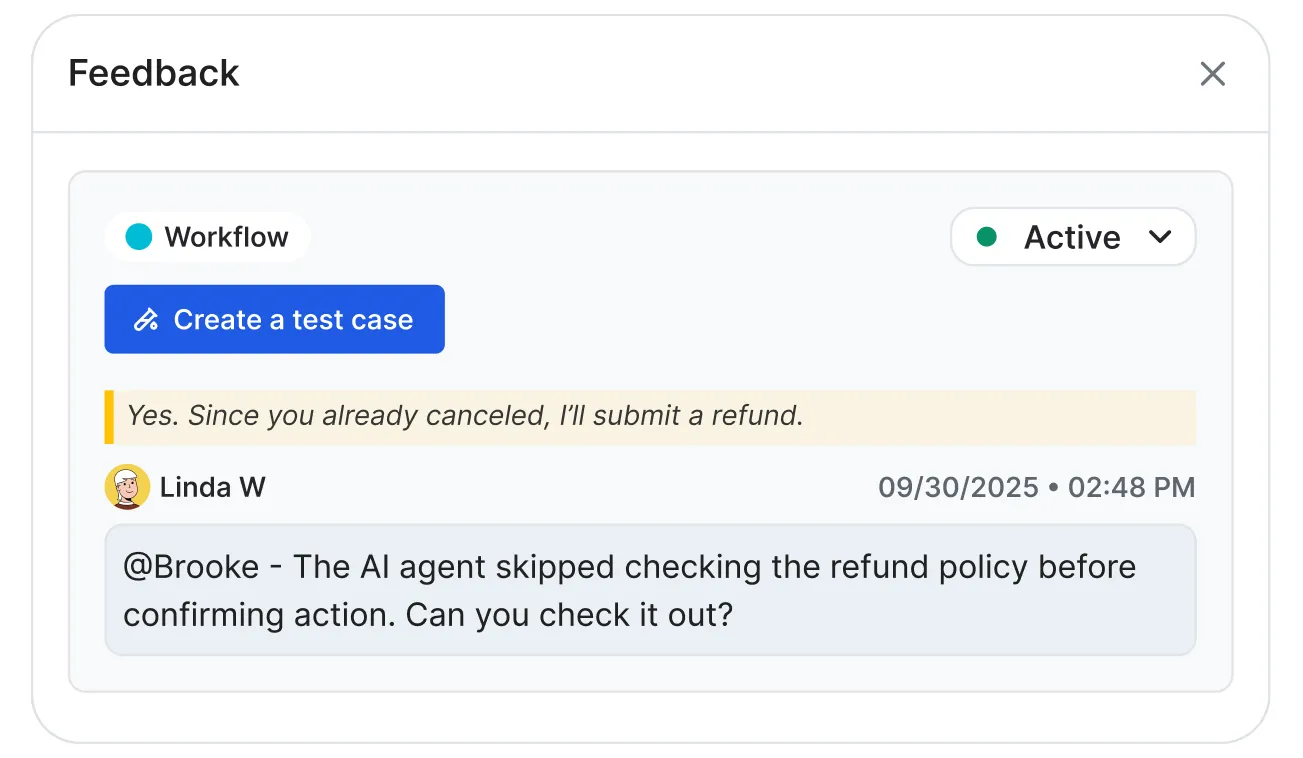
Where Single-Layer Evaluation Breaks Down
Most teams evaluate too late and too narrowly. An AI agent gets built, prompts are tested with a one-time set of evaluators and manual testing, outputs look acceptable, and the agent ships. The evaluation is a one-time gate — limited to scenarios the team imagined in advance. An agent that looks solid against an extensive, curated test set can still show gaps at production scale.
Tests miss unanticipated inputs.
After a routine model update at a financial services client, Cresta's regression suite flagged that the agent had begun omitting a required compliance disclaimer. The issue was fixed in hours. Without automated monitoring, it would have surfaced through a compliance review—or not at all.
In a security deployment, some of the users offered their codeword for authentication as “codeword” or “pardon”. The AI Agent did not call its function tool, as it believed the codeword was not a valid input.
Real users don't follow the ‘happy path’; they digress, change topics, contradict themselves mid-conversation, and generate unanticipated inputs.
With one of our airlines customers, users often start with a goal (e.g., booking a flight), but then switch topics mid-booking process to change passenger inputs, clarify mileage status perks, or make action-based requests to merge their miles before payments - each of these requires the AI Agent to update tool parameters, draw from the knowledge base without loss of state-tracking on where we are in the purchase, and call a nested operating procedure with its own set of function tools.
Reviewers miss patterns visible only at scale
A small portion of customers forget to hang up, staying silent for >1 hour while the AI Agent keeps clarifying what it can help with, while overhearing background conversation.
What the Series Covers
This is the first of four posts walking through Cresta's field-tested evaluation lifecycle:
- Part 2 — Evals informed by real-world data: How Cresta analyzes real conversation data — before writing a single test — to determine how users actually behave, not how the spec expects them to. That analysis gets translated into a precise, aligned checklist of what the agent interaction must get right.
- Part 3 — Constructing a reliable test stack: Three distinct automated test layers cover ideal scenarios, behavioral edge cases, and known failure patterns. A dedicated calibration step ensures the automated grading system itself is accurate — because a mis-calibrated judge is its own kind of failure.
- Part 4 — Where real evaluation begins: The work doesn’t stop at launch. Every agent change is tested against the full test suite before going live, and a sample of real production conversations gets graded continuously — so problems are caught before they reach customers
Stay tuned for the rest of our series - and don't miss 13 AI Agent Use Cases to Improve CX.



