





Enterprises want to automate more of the customer experience, but struggle to see the underlying structure of how work actually gets done in contact centers. Without a clear view of how workflows unfold across interactions, it’s difficult to determine what can and should be automated and how to implement it reliably.
Specifically, while organizations typically understand the high-level reasons why customers call, they lack visibility into the intricate, undocumented micro-steps agents take to resolve those issues. They cannot easily map the tribal knowledge, complex branching logic, necessary contextual probing, and system workarounds that human agents routinely navigate. When these in-between steps are missing, translating real interactions into automation becomes unreliable and risky.
Automation Discovery addresses this by analyzing conversation data at scale to extract structured workflows from noisy interactions. It identifies repeatable patterns, reconstructs how tasks are completed step by step, and generates a blueprint for automation. This requires combining language understanding with pattern mining and deterministic analysis.
To build reliable automation, teams need more than just high-level summaries of conversational trends; they need to systematically mine structured, repeatable patterns directly from thousands of noisy, unstructured conversations. Automation Discovery programmatically breaks down these raw conversations to map the exact sequences of actions, structural dependencies, and edge cases. The result is a clear, evidence-backed representation of the core flow – transforming messy conversational data into a rigid workflow blueprint that teams can inspect and confidently act on to design and deploy AI Agents.
This serves two main purposes:
- For data exploration, it helps teams understand common conversation paths, deviations, and sources of variation.
- For automation, it provides a reliable blueprint of steps and decision points needed to design and implement workflows.
Automation needs a discovery layer
Production AI agents require a clear, reliable structure to operate, but this structure is not easily visible. In practice, workflows are messy where people take different paths, handle edge cases inconsistently, and adapt based on context, making it hard to clearly understand how work actually flows end-to-end.
A discovery layer is needed to make this structure visible. It surfaces how workflows actually execute at scale, revealing common paths, variations, and deviations that are not easy to capture. This allows teams to understand which parts of the structure are stable enough to automate, where complexity exists, and how to design systems that can handle variations.
Inside the machine learning system
At a high level, the system performs three tasks: it infers a core conversation flow from conversation transcripts, measures how real conversations adhere or vary around that workflow, and estimates automation feasibility from the resulting structural signals.
Historical conversations already contain the evidence of how work actually gets done: the common sequence of steps, the points where conversations branch, the exceptions that appear repeatedly, and the operational steps implied by what agents say and do. Automation Discovery uses LLMs together with deterministic analysis to extract that structure and turn it into a usable representation.
.png)
1. Inferring the core conversation flow
The first task is to identify the dominant flow that appears across a set of related conversations.
The system compares many examples to identify the sequence of actions and transitions that occur most consistently, rather than relying on any single transcript as an authoritative example. Across conversations that share the same underlying task, stable patterns tend to emerge: greeting, identification, diagnosis, resolution, escalation, and so on. Even when phrasing varies, the structure is often remarkably consistent.
By aggregating these patterns, the system synthesizes a core flow – a representation of how the workflow typically unfolds in production. This flow is not copied from any one conversation; it is constructed from recurring behavior across the dataset, preserving the most common path while filtering out noise and one-off variation.
The flow is represented as a sequence of abstracted phases, for example:
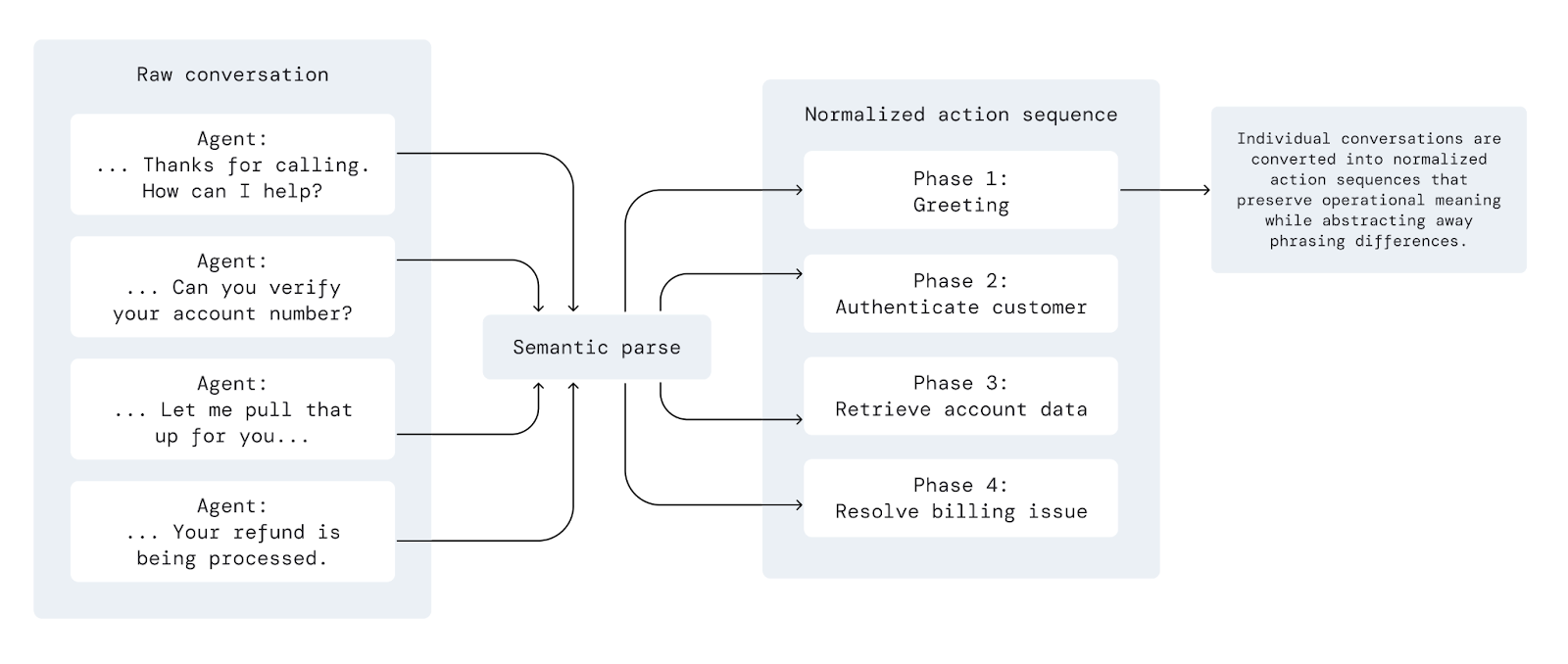
This abstraction layer matters because raw conversations contain enormous stylistic variation. Different agents may phrase the same step differently, or combine multiple steps into a single utterance. The system needs to normalize those surface differences without discarding operational meaning.
These core flows are structured hierarchically with two levels: phases and steps. The system statistically determines whether phases and steps are required or optional. A phase that appears in almost every conversation is considered part of the core flow (required). Conversely, a phase appearing only in a smaller, consistent subset of conversations is modeled as conditional (optional).
Importantly, the resulting flow is not treated as a rigid sequence. In real conversations, phases may appear in slightly different orders, repeat, or be skipped (if optional) depending on context. The system reflects this by treating the flow more flexibly – as a set of phases that define the workflow, rather than a strictly ordered script.
2. Inferring operational dependencies
Automation feasibility depends not just on conversational structure, but on what needs to happen behind the scenes e.g., what tools to use to complete a real-world task.
The system looks for evidence of operational dependencies directly in the conversations. When agents say things like “let me check your order,” “I’ll submit a claim,” or “I need to verify eligibility,” those patterns often indicate interaction with backend systems.
Automation Discovery aggregates and identifies conversational signals to estimate where integrations are likely needed. These required integrations are represented as tools (in LLM terminology), which are linked to specific steps within the core conversational flow.
This provides an early view into implementation complexity, even without direct access to the customer’s systems. A workflow that appears simple conversationally may still be difficult to automate if it depends on multiple systems, while a more complex workflow may be easy to automate if it is operationally self-contained.
3. Measuring deviations from the core flow and workflow variability
Once the core flow is established, the next step is to understand how real conversations differ from it. Rather than attempting to explicitly model all possible branches, the system focuses on identifying and analyzing the parts of conversations that do not fit into the inferred core flow. These out-of-pattern segments – referred to as deviations – are the primary signal for understanding workflow variability.
This process is implemented in three stages:
- The system scans the original conversations and identifies messages that do not align with any of the phases in the core flow. These messages represent places where the conversation diverges from the core flow structure – for example, additional verification, unexpected customer requests, retries, or escalation-related steps. At this stage, the goal is simply to isolate all such “raw deviation” messages without attempting to interpret them yet.
- The system analyzes these raw deviations across the dataset and groups them into recurring categories. Because similar types of divergence tend to appear across many conversations, clustering these messages reveals common patterns of variability – such as transfers between teams, repeated authentication attempts, or policy exceptions.
- The system attempts to assign each raw deviation message to one of these inferred categories. Messages that match a known pattern are grouped accordingly, while truly unique or rare cases are left unassigned. This ensures that the system captures both recurring sources of complexity and one-off edge cases without forcing everything into predefined buckets.
This approach produces a structured view of how conversations vary around the core flow. Workflows where most conversations map cleanly to the core phases – with relatively few deviations – tend to be more predictable and easier to automate. Workflows with a high volume of deviations, or many distinct deviation categories, indicate greater variability and typically require more careful handling.
Importantly, deviations are not treated as errors. Rather, they are treated as evidence of how the workflow behaves in practice. Some deviations reflect minor variation that can be absorbed into automation logic, while others represent meaningful edge cases that require explicit design (e.g., introduction of a new flow phase or a step). By surfacing both the frequency and the nature of these deviations, Automation Discovery enables teams to reason about complexity directly.
Once Automation Discovery groups raw conversational deviations into clear structural categories, teams need to quickly understand the underlying reasons behind those alternate paths. Cresta AI Analyst can add value here as the conversational insight engine for your workflow data. Instead of manually reviewing dozens of transcripts to investigate a sudden spike in policy exceptions or complex handoffs, users can simply click into that specific deviation bucket and ask ad-hoc, natural language questions to instantly diagnose the root cause. By seamlessly connecting structural discovery with AI-driven root-cause analysis, teams can confidently determine whether a deviation is just conversational noise or a critical workflow gap that needs to be addressed before building their AI Agent.
4. Estimating automation feasibility
Finally, the system combines these signals into an overall automation readiness score – High, Medium, or Low.
The score is driven by structural and operational signals observed in the data, including the frequency and nature of deviations, as well as the level of inferred integration complexity. Together, these provide a more reliable basis for prioritization than anecdotal judgment or surface-level metrics alone. The readiness score is intentionally an estimate, not a definitive verdict. It reflects what can be inferred from conversation behavior, but it does not capture all aspects of implementation reality. Users can adjust the score based on their own knowledge of the environment, constraints, and goals.
In practice, the score serves as a structured way to compare workflows. It helps teams quickly identify which use cases are likely to be straightforward, which require more careful design, and which may not be strong candidates for automation in their current form. The score is an estimate based on observed patterns in the data, not a definitive decision. Teams can adjust the score based on their own context, such as business priorities, constraints, system readiness, and risk tolerance, using it as a starting point rather than a final decision.
Designing the discovery experience
Automation Discovery was designed to help teams understand complex conversational data and trust what the system is doing. The experience is built to reveal structure by surfacing complexity and turning unstructured conversations into artifacts that can be explored, inspected, and verified.
The design is grounded in the output layer of the machine learning system. The model produces a structured representation of the workflow, and the UX directly reflects this structure through flows, deviations, and supporting examples.
This approach allows users to move between high-level structure and underlying conversations, exposing the evidence behind each insight. By making these connections explicit, the system helps users understand why certain patterns and deviations appear.
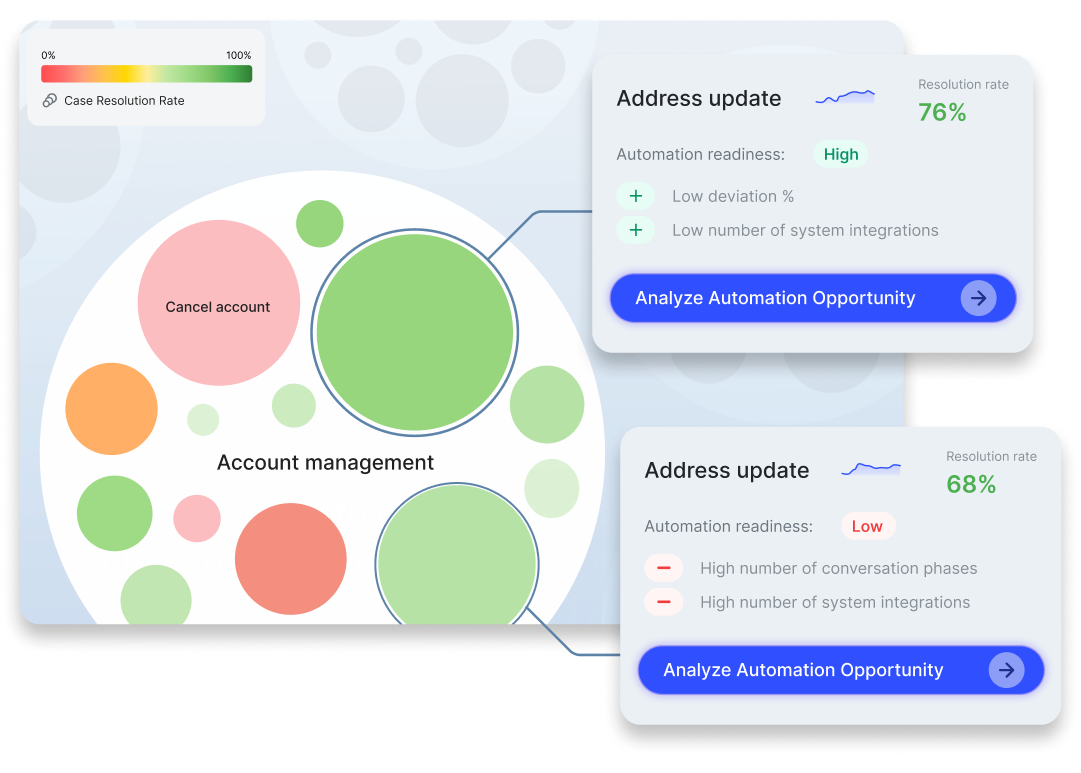
Starting from Topic Discovery
The journey begins with Topic Discovery to ground the experience in real operational signals. Users assess conversation clusters using Cresta metrics like volume, AHT, CSAT, and resolution, where high-volume, high-resolution topics often emerge as strong candidates for automation. From a selected topic, users can trigger Automation Discovery to move from high-level metrics into understanding how the work is actually performed.
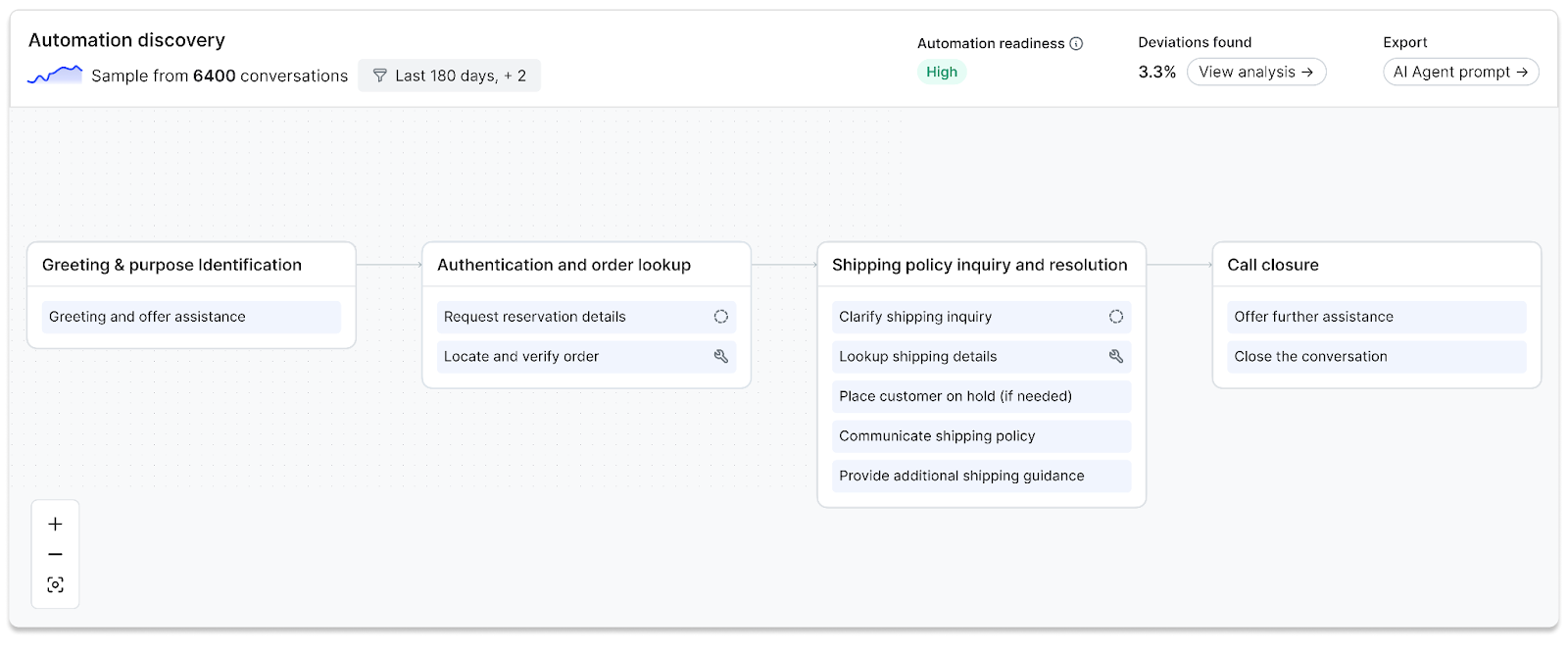
Structure expressed as a flow
The discovered workflow is presented as a structured flow. Phases appear as high-level blocks, with steps nested within them. Optional markers indicate where paths diverge, and inferred system dependencies highlight where external tools are involved.
The experience supports multiple levels of understanding. Users can scan phases to grasp the overall shape of the workflow or drill into steps to see how the work is executed. By linking structure to underlying conversations, the flow remains both understandable and grounded in evidence.
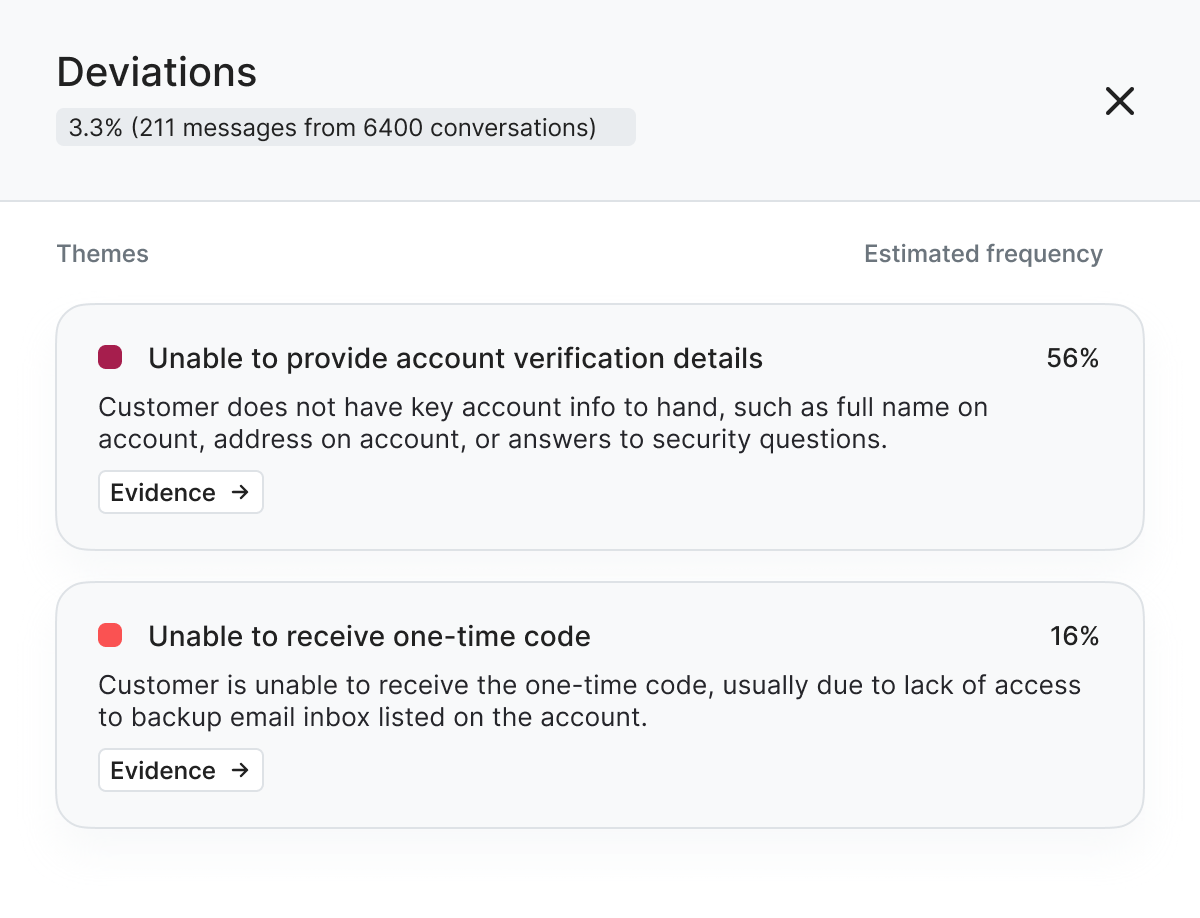
Analyzing deviations in a workflow
Real customer conversations with human agents are not prescriptive and often diverge from a defined workflow. The deviation view is designed to analyze these breakpoints. It surfaces the overall deviation rate, groups repeated deviations into clusters, and shows their percentage contribution, helping users quickly identify where variation is concentrated.
Each deviation is grounded in real conversation examples. Users can inspect these to determine whether a pattern is noise or a true automation blocker, such as a policy exception, handoff, or system failure. This helps teams move from seeing variation to understanding it and deciding what needs to be handled in automation.
AI Agent Prompt Export
Once users have explored the workflow and inspected its deviations, the experience moves toward action. Automation Discovery can export a structured draft prompt derived from the workflow, serving as a scaffold for AI agents.
The export transforms the discovered structure into an artifact that can be used to build. Phases, steps, and dependencies are carried forward into a structured prompt that teams can inspect and extend.
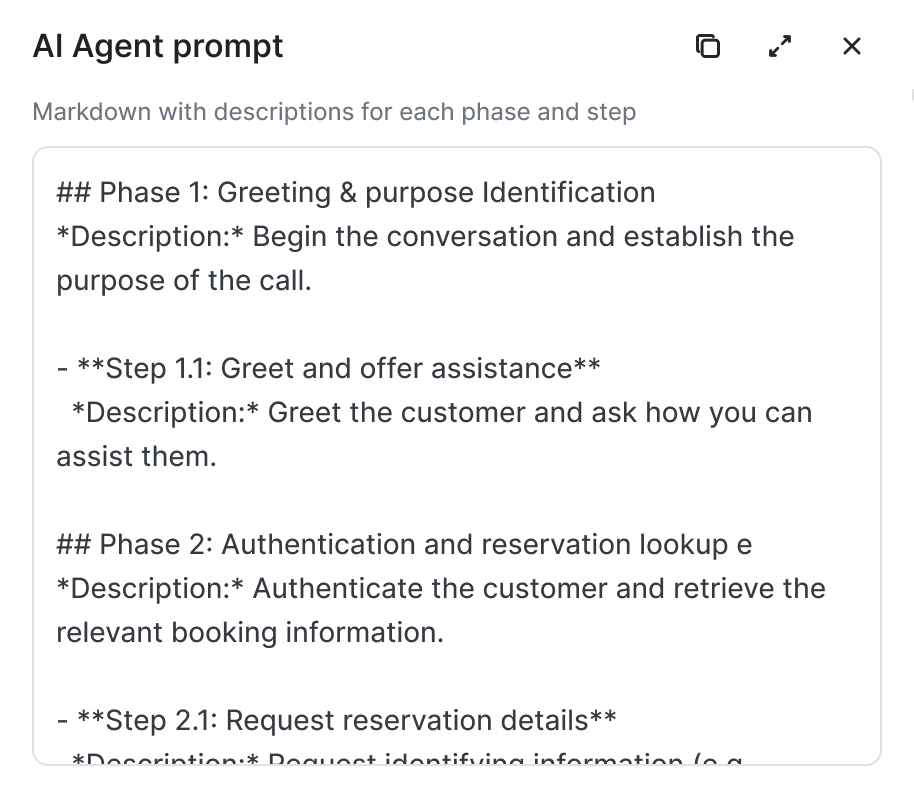
The experience moves from topics → flows → deviations → prompt export, turning raw conversations into workflows teams can actually inspect and build from. This is the missing discovery layer. Production systems need a clear, reliable structure representing phases, steps, deviations, and dependencies but most teams don’t have this mapping today
Automation Discovery pulls that structure from customer interactions and reveals the conversation flow path, where these paths could deviate, and why certain workflows are better candidates for automation. For automation, teams can use this blueprint to design agents, define workflows, and plan required integrations.
The shift is straightforward: instead of guessing what to automate, teams start with what’s actually happening.
To see what Automation Discovery looks like in action, schedule a personalized demo today.


