PART 2 | CRESTA’S AI AGENT TESTING & EVALUATIONS APPROACH
Most test suites are built against an imagined version of user behavior. They map the ideal interaction from start to finish, enumerate the edge cases a product team can anticipate, and call it coverage. The problem is that customers don't follow the spec. They digress, chain together unrelated intents, and escalate for reasons that don't map neatly to Standard Operating Procedures (SOPs). An evaluation framework built without grounding in real data tests the world the team imagined, not the one customers actually inhabit.
That's why Cresta's evaluation process begins with the data: specifically, the corpus of real, historical conversations the AI Agent will eventually have to handle. Before a single test is written, our discovery tools answer a deceptively simple question: what do users actually do?
The answer is almost always more complex than the product requirements suggests, and the gap between the two is exactly where production failures originate.
In Part 1 of this blog series, we introduced the Swiss Cheese model: the idea that no single evaluation layer is sufficient, and that reliability comes from stacking imperfect layers until the holes don't line up. Part 2 is where that framework meets the data.
Building Test Coverage
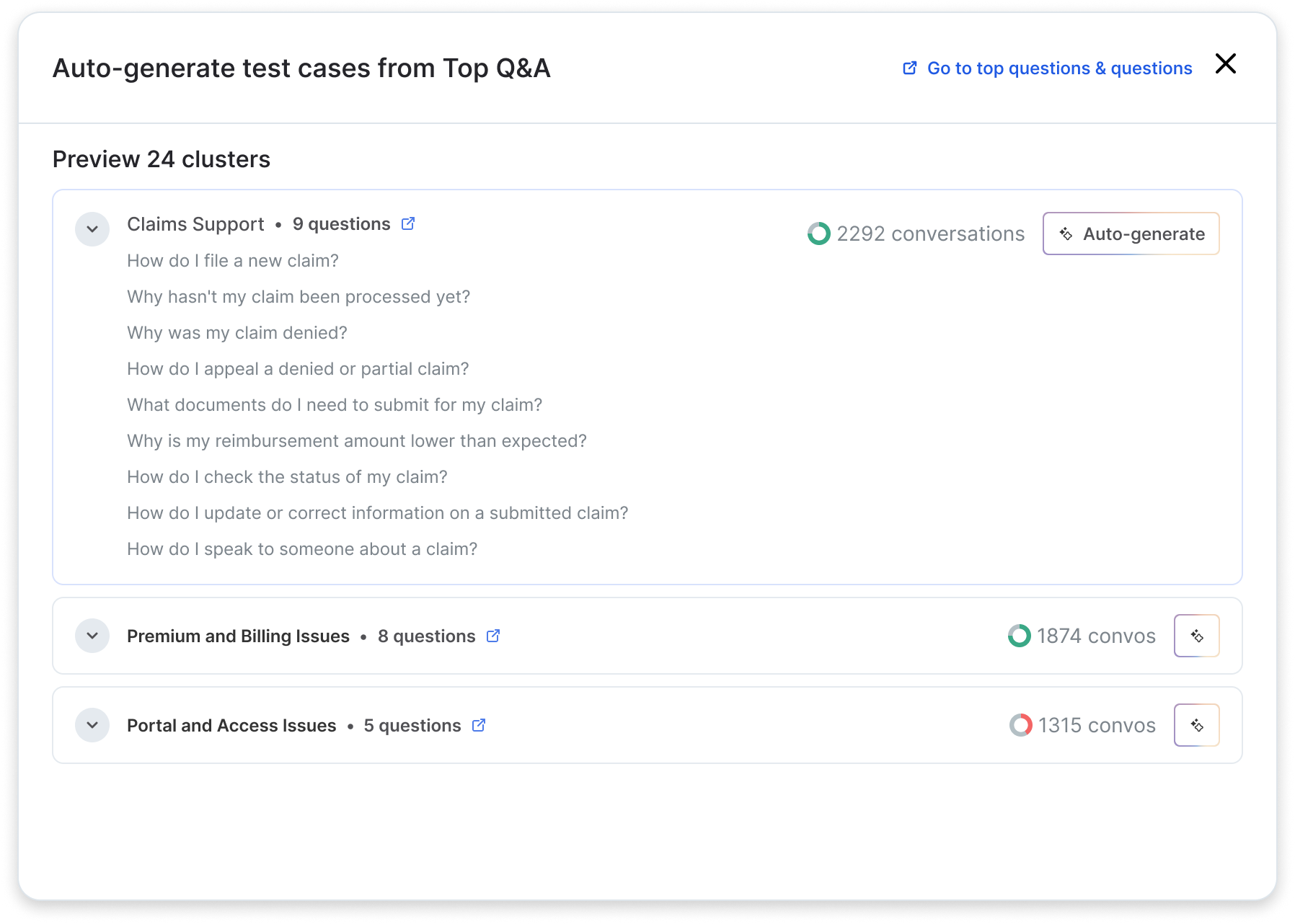
The “Discovery” phase of Cresta’s development lifecycle always closes with a test plan: a structured, comprehensive outline of scenarios the evaluation suite must cover.
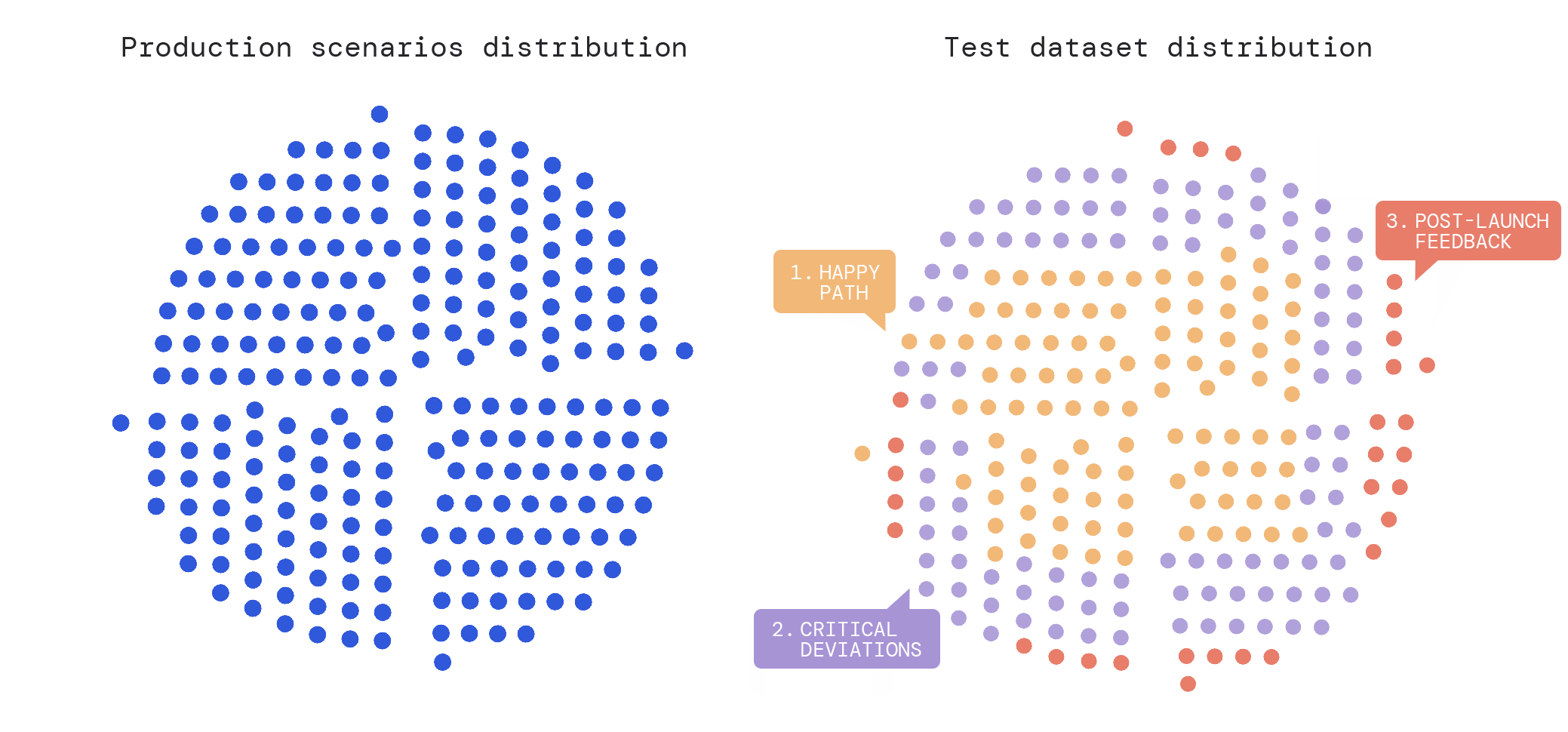
The data model organizes scenarios into three types:
- Happy path scenarios represent the ideal interaction from start to finish. These reflect typical customer support transcripts, and are addressed early on in the “Build” phase of the AI Agent development lifecycle.
- Critical deviations include common divergences from the expected conversation flow, as well as high-stakes edge cases. These often appear as escalation requests, clarifying questions, compliance-sensitive moments, and quirks in the business’ operations that trigger unexpected behavior.
- Cresta’s Automation Discovery and AI Analyst toolsets quantify what percentage of conversations follow each deviation path. We address these test scenarios prior to User Acceptance Testing, which is a stagegate to launching.
- Post-launch feedback addresses scenarios that result from human-AI interactions. These include the user’s expectations for the AI’s speech style, which are reflective of a business’s customer demographics, as well as new language pattern and different user behavior.
- The Cresta team drives fast iteration and converts these into regression tests that protect against recurrence.
By launch, the team has produced two assets that many evaluation programs never reach:
- A data-grounded understanding of real user behavior, and a shared list of Agent behavior requirements, agreed to by both Cresta and the client.
- Auto-generated Synthetic Customers that can be used in simulations, which are used to augment scenarios determined by the human mind.
Four Inputs Converge Into One Cohesive Dataset
Four inputs feed into our AI-generated test sets, each addressing a different angle of input. When combined, these assist in creating a thorough testing dataset.
1 - The Requirements Adherence List
The Binary Requirements List is our ultimate evaluation contract: the precise, shared definition of what “good” means for this agent.
To start, Cresta aggregates the customer’s Standard Operating Procedures (SOPs), qualitative guiding principles, and AI Agent Product Requirement Document (PRDs). A LLM synthesizes these into a “Requirements Adherence” list, which is then validated by the Customer’s domain experts.
This Requirements list becomes a blueprint for developing “Happy Path” simulations that cover the Agent’s key requirements.
- Each requirement is tagged with a priority order, such as must-have or a nice-to-have. These requirements can be run on simulated conversations, as well as production AI Agent conversations, producing a scored report on how well the Agent adheres to the agreed upon requirements.
- Each requirement is grounded in evidence from the real, historical conversation corpus: the LLM is prompted with representative transcripts and asked to surface verifiable, binary pass/fail criteria.
- Human-in-the-loop (HITL) review is non-negotiable. HITL reviews prevent the creation of test requirements that reflect procedures & documents, but are missing operational context and valid edge cases.
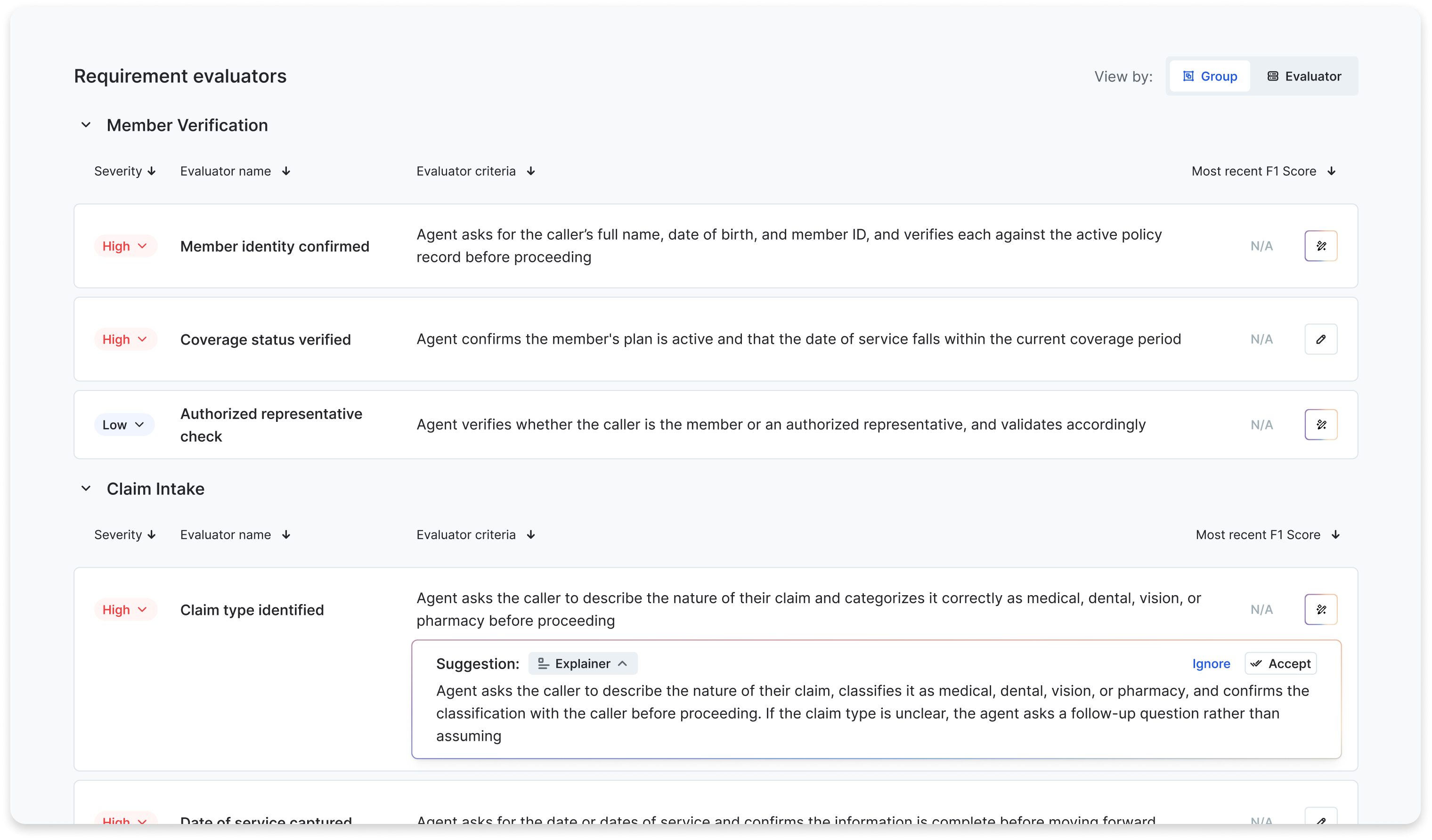
2 - Synthetic Customers
Synthetic Customers are realistic, representative customer personas and synthesized scenarios extracted from our customers’ real, historical conversations.
How do we create synthetic customers? Cresta’s Insights suite clusters historical transcripts by intent and behavioral pattern to produce a set of representative customer archetypes. Each persona carries a distribution of likely intents and phrasing variations, seeding the Simulated Visitors with inputs that reflect actual user populations rather than imagined ones.

Field example 1: Oftentimes out-of-box guardrails are tuned to generic support use cases, advising the AI Agent against offering medical or financial. For our healthcare and financial services Agents, Cresta’s Synthetic Customers can assess where the requirements are too rigid, allowing the forward-deployed team to tune the guardrails to not trigger for intended use cases.
3 - Knowledge question-answer pairs
The Knowledge Base itself becomes our third source of test data. Cresta leverages AI to generate question-answer pairs and simulations based on your knowledge source. These test cases can be easily re-generated after edits to your source-of-truth, reducing the time to deployment for tweaks.
4 - “AI Feedback” to capture post-launch feedback
Real edge cases from customer conversations round out the dataset during Post-Launch Feedback. Customers use our AI Agent Feedback feature to drive feedback cycles/ Iteration loops for the AI Agent.
- We have one-click workflows to turn a customer conversation into a new test case. This feature allows Cresta to capture the end user’s verbatim wording, previous context, and even API outputs (cached for future simulations) for regression testing.
- As evaluators surface ambiguous cases, the requirements list is tightened: edge cases that exposed under-specified criteria become new test inputs, and the evaluator itself is updated to reflect the resolved interpretation. The loop continues until evaluator agreement rates stabilize.
The anatomy of a test case
Each test case structures inputs that drive simulated visitor testing. Each prompt specifies:
- A description of the visitor (end customer) and how they should behave
- An entry “intent” i.e., why the end customer is contacting your business
- Any contextual constraints (e.g., prior transfer history, end customer’s account status).
The simulator then executes the full multi-turn conversation against the agent under test, producing transcripts that evaluators can score at scale.
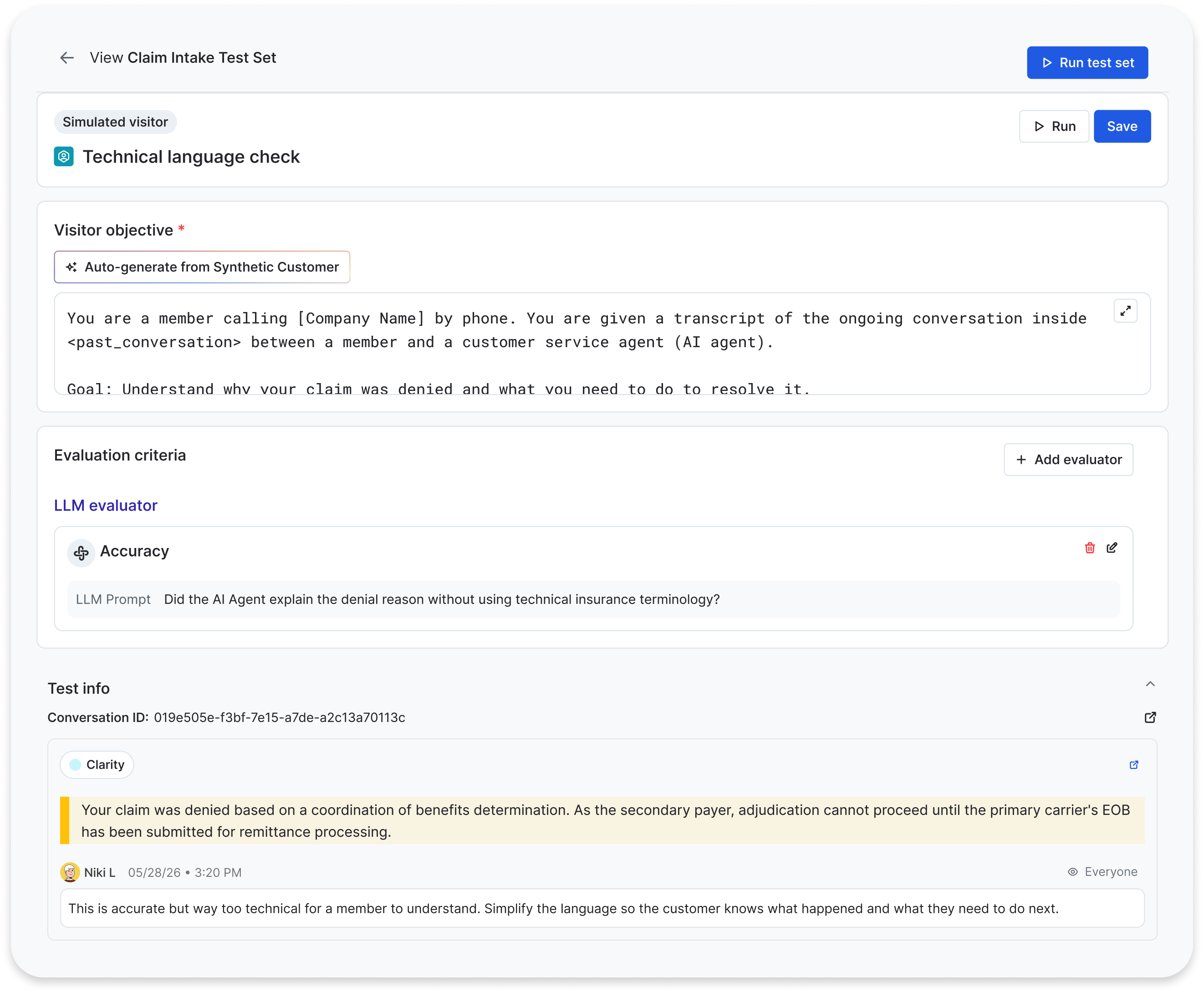
Learnings from the field
Finding failure modes the spec would never surface
Both Cresta's forward-deployed team and our Customers’ admins use Cresta AI Analyst—a natural-language, AI-assisted analysis solution—to dissect the conversation corpus with targeted questions:
- “What do customers say immediately before requesting a supervisor?”
- “Which phrasing variants correlate with the agent giving an incorrect policy answer?”
These patterns rarely surface in standard reporting, but they are exactly the failure modes that emerge in production.
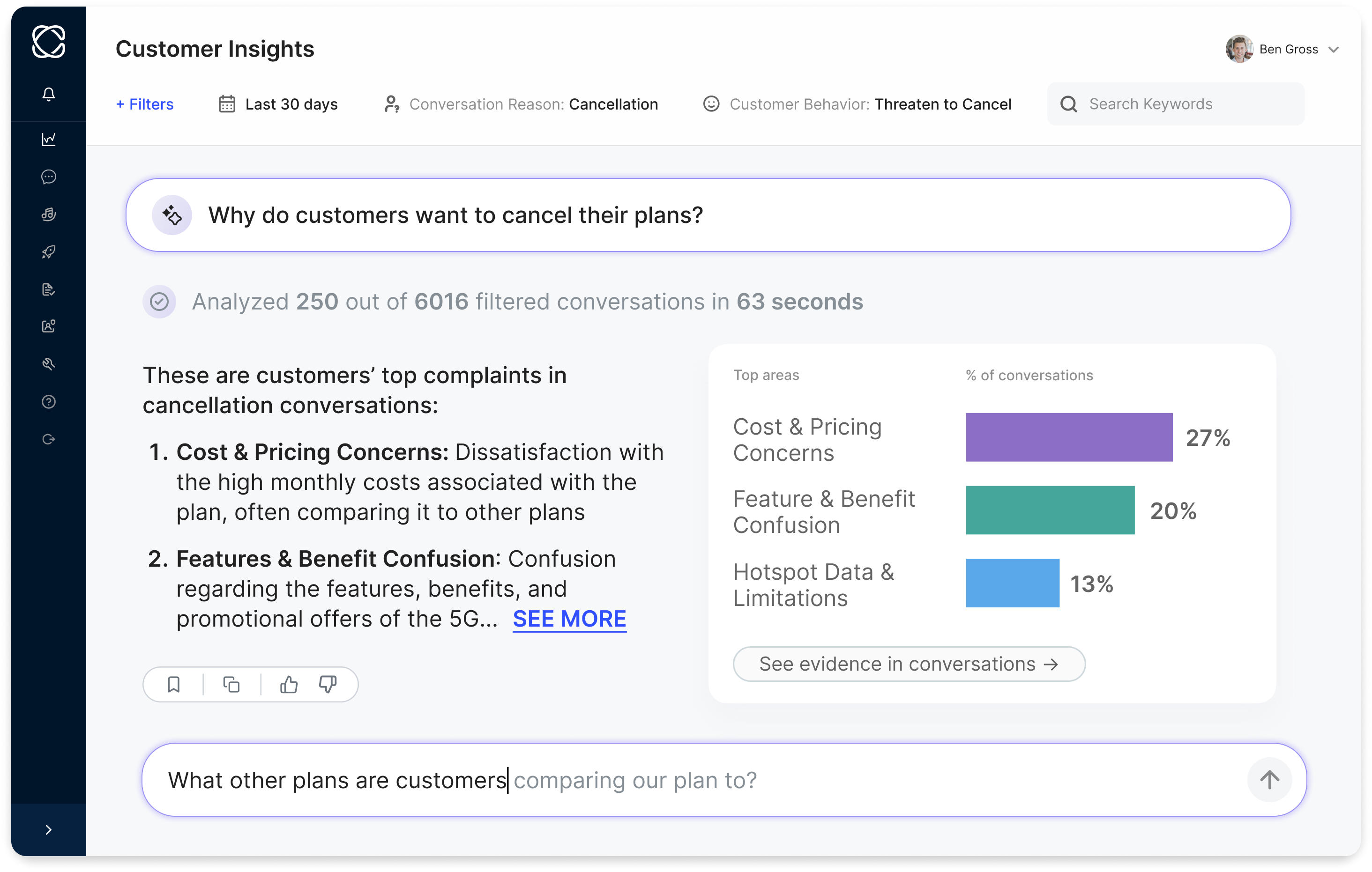
Field example 2: At a telecom client, analysis revealed that customers who had already been transferred once were significantly more likely to demand escalation within the first two turns of the next interaction. That insight produced a specific requirement and a targeted test, neither would have been written from a product spec alone.
Field example 3: Using Synthetic Customers and real conversation analysis, a fast-growing fintech company with over 8.2 million customers discovered that up to 10% of callers wanted support in Spanish, which they had not previously recognized. They updated the greeting and routing experience to clearly direct Spanish-speaking customers to a different Agent experience. The result was a 15% improvement in containment while also getting customers to the right support channel.
This is the point of grounding the test suite in real data: not to validate the scenarios the team imagined, but to discover the ones they didn’t.
Up next: Part 3 — How Cresta Grades Its Agents: Evaluators in an LLM world
A testing suite is only as reliable as the evaluators grading it. In Part 3, we cover Cresta’s evaluation framework: how Cresta converts the adherence requirements into LLM-as-judge evaluators, and pairs them with deterministic tool-call verifications. Imprecise evaluators don’t just produce noisy scores, it can erode confidence in the entire testing program at scale.